先看一下题目

抓包
首先翻页
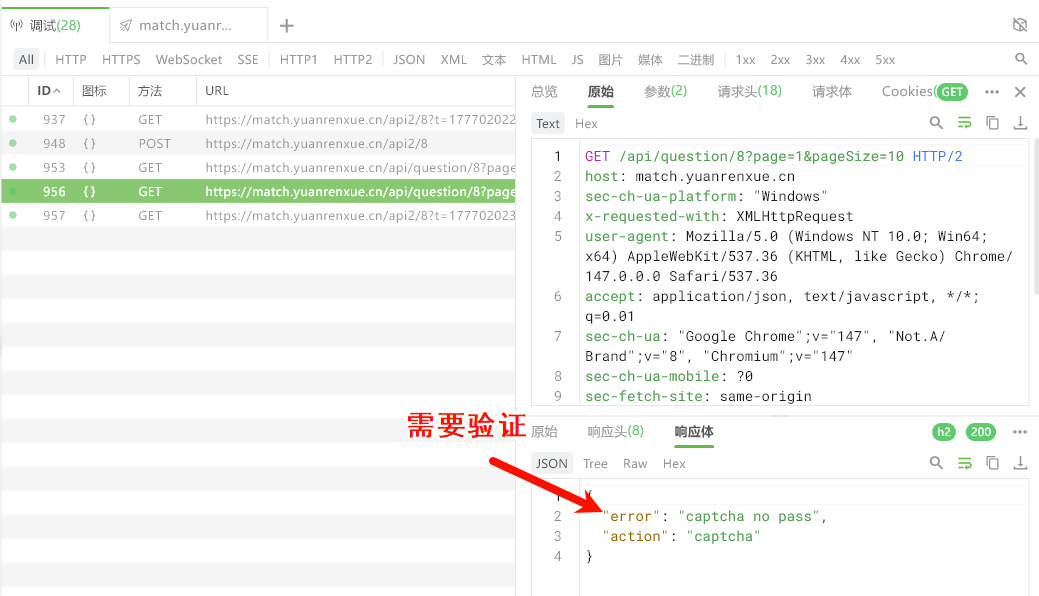
刷新一下验证码
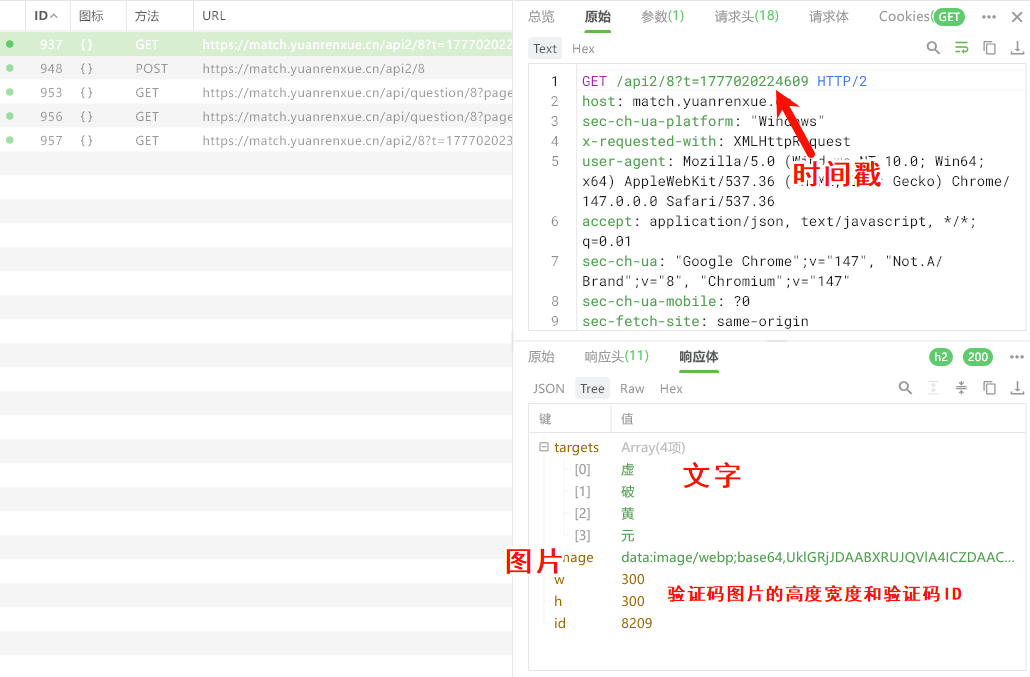
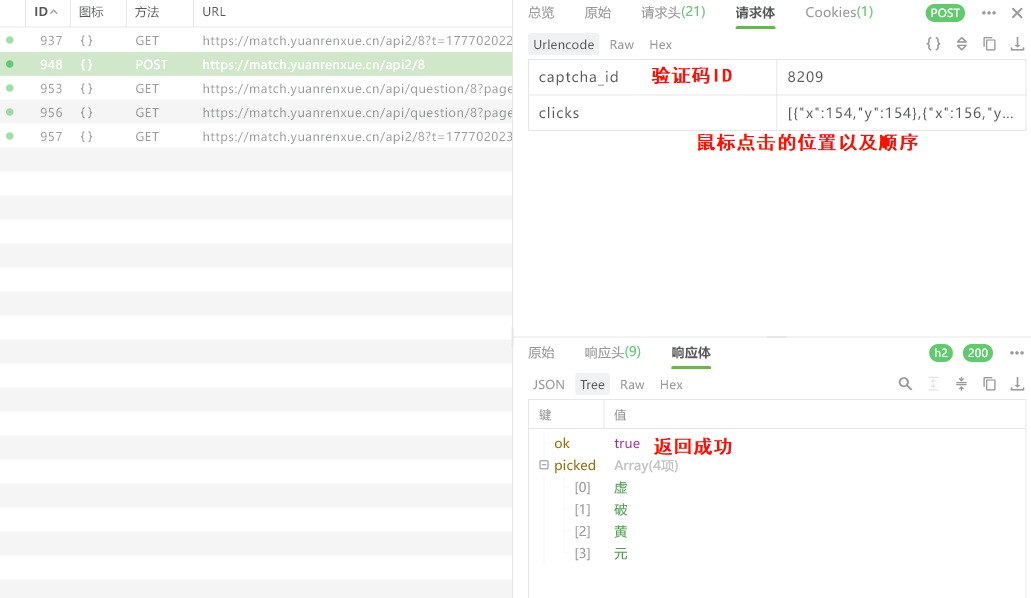
手动选择后提交验证码
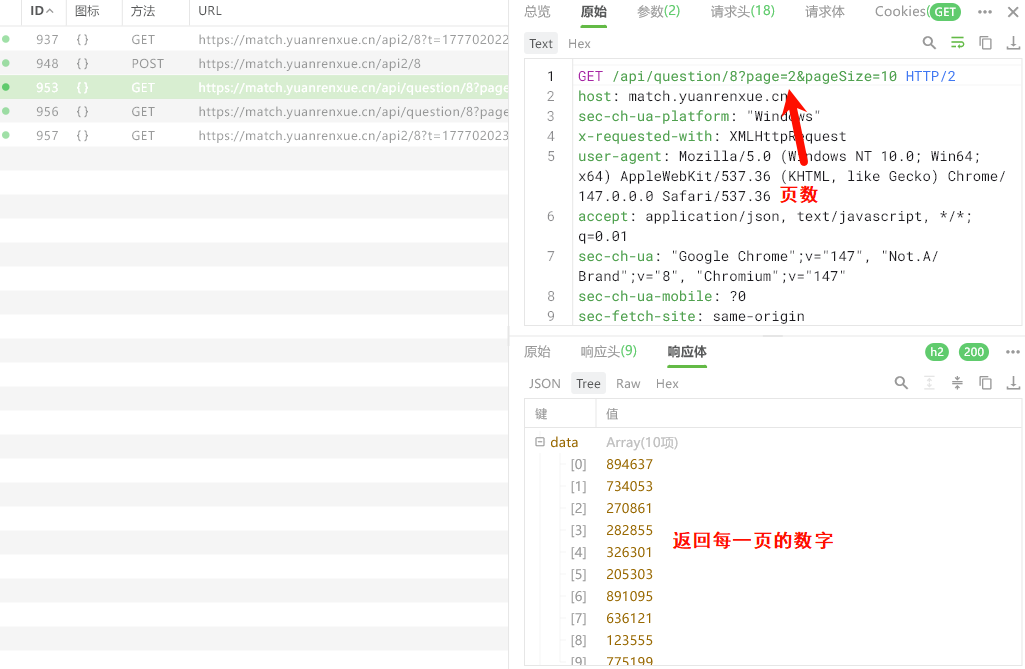
然后翻页
总结一下
翻页的时候如果返回的action为captcha则为需要过验证码
请求获取验证码
- image为图片的base64编码
- targets为点选的文字数组
- w为图片的宽度
- id为验证码的ID,提交的时候需要
然后提交验证码的ID和点击的位置,成功ok返回true
然后再次请求页数就可以了
识别
问题就在于识别文字,之前用到过CnOCR的库,因为可以在线测试,所以还使用它。
最初的想法是直接一整张图片提交,识别,但是识别率感人
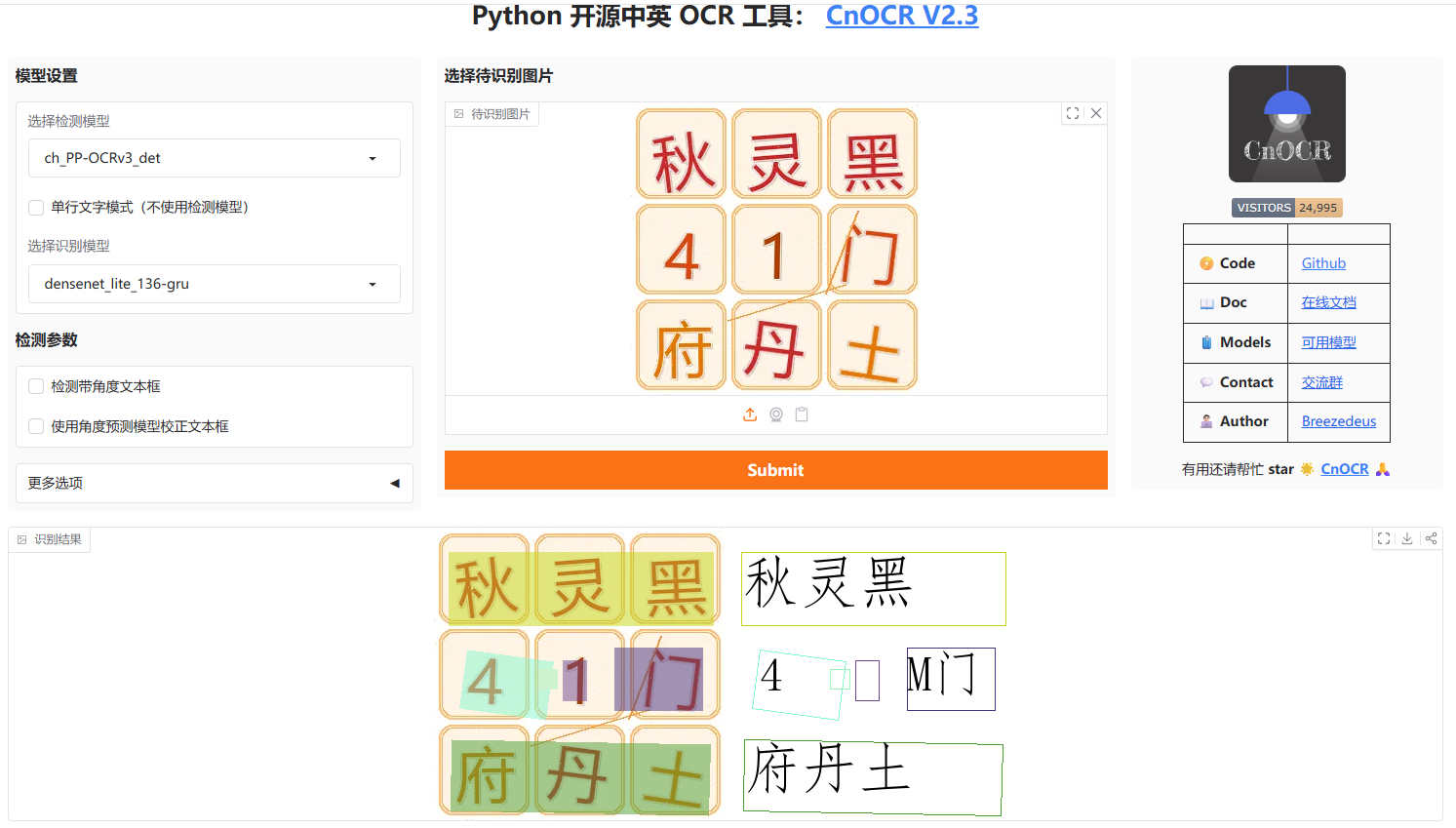
故而放弃,使用另一种方法。
观察验证码是正方形图片,每一个字分布的十分平均,所以可以九宫格分割图片,分割为9份,然后一份一份识别。
测试
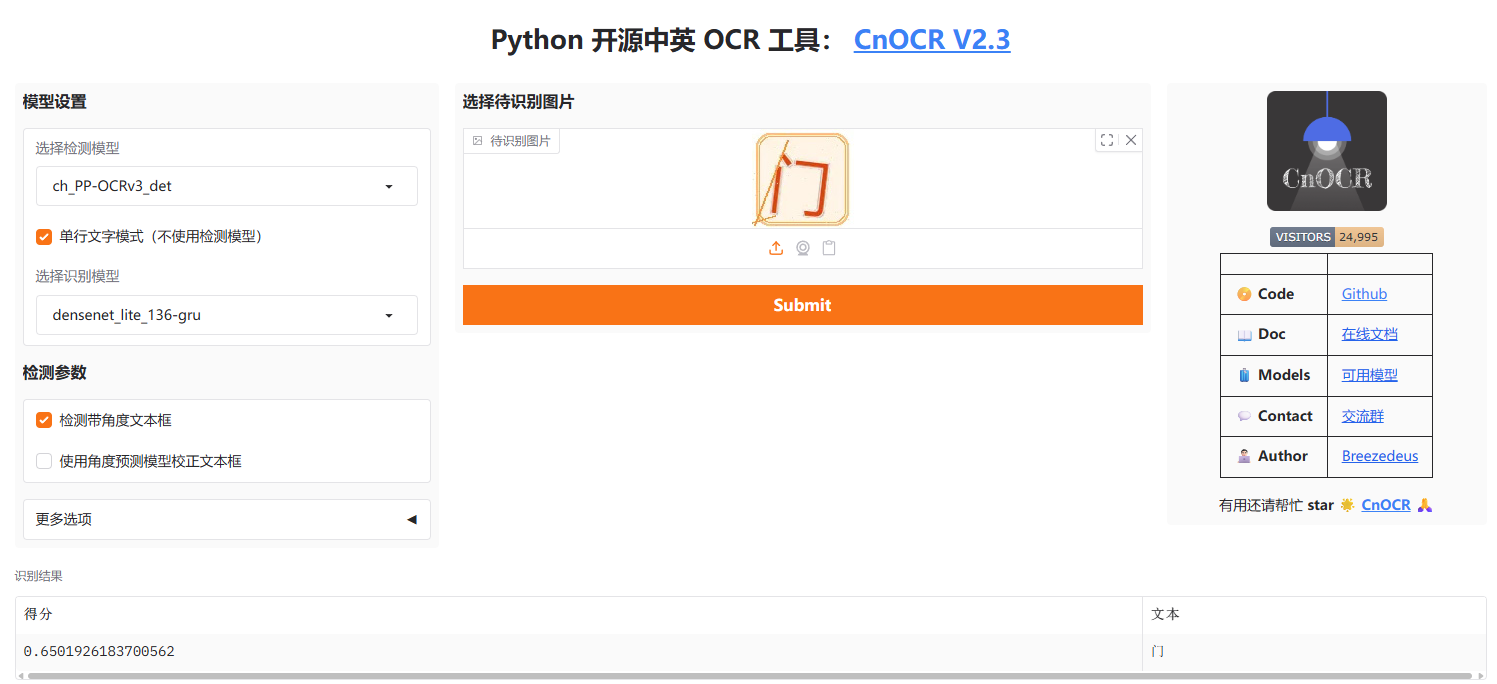
发现效果还不错,就决定使用此方案。
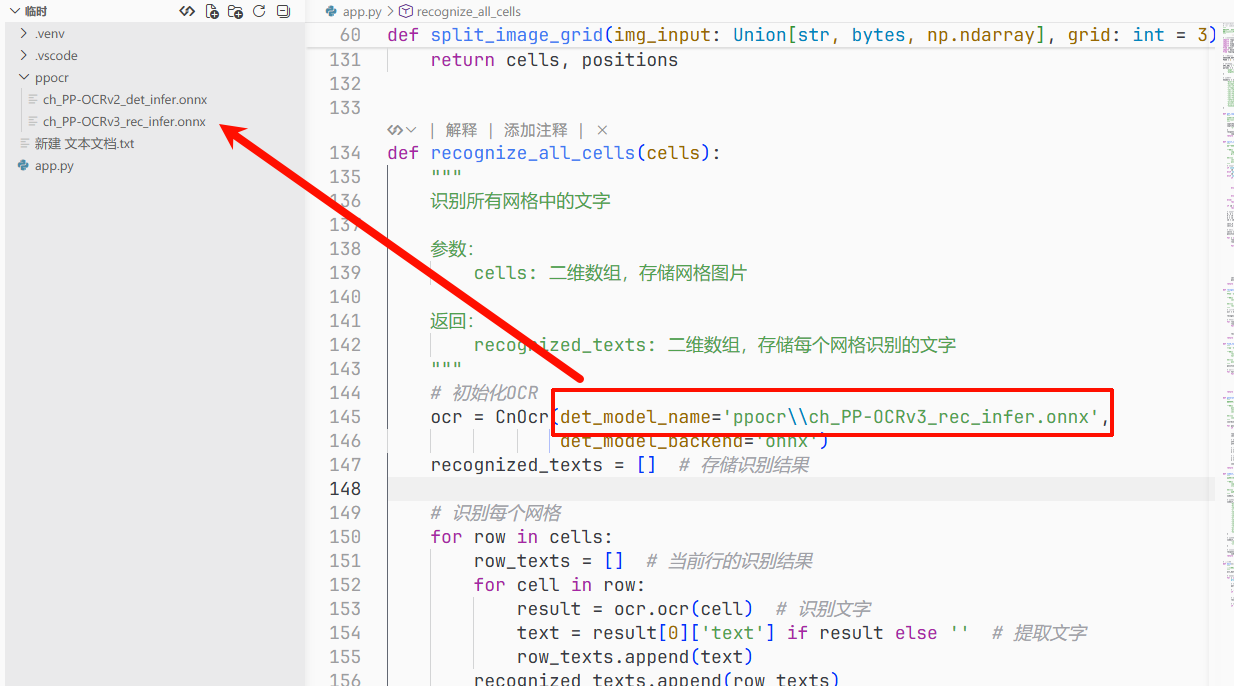
然后开始初始化下载并且加载模型
运行结果
本次AI参与了大量代码的编写,运行结果:
===== 处理第1页 =====
识别结果: [['张', '地', '紫'], ['乘', '月', '基'], ['金', '暑', '7']]
目标文字: ['紫', '金', '张', '基']
目标位置: [(0, 2), (2, 0), (0, 0), (1, 2)]
点击坐标: [{'x': 277, 'y': 75}, {'x': 67, 'y': 261}, {'x': 77, 'y': 82}, {'x': 234, 'y': 164}]
提交验证码...
提交结果: {'ok': True, 'picked': ['紫', '金', '张', '基']}
重新请求数据...
数据请求结果: {'data': [594577, 850977, 889329, 532710, 114010, 368072, 294701, 538058, 803509, 224231]}
第1页数据: [594577, 850977, 889329, 532710, 114010, 368072, 294701, 538058, 803509, 224231]
===== 处理第2页 =====
识别结果: [['金', '盈', '乘'], ['气', '', '藏'], ['玄', '日', '木']]
目标文字: ['0', '木', '日', '乘']
目标位置: [(2, 2), (2, 1), (0, 2)]
识别不完整,只找到3个目标文字,需要至少4个,重新请求识别...
识别结果: [['生', '往', '道'], ['海', '黄', '宿'], ['神', '川', '道']]
目标文字: ['道', '往', '神', '海']
目标位置: [(0, 2), (0, 1), (2, 0), (1, 0)]
点击坐标: [{'x': 249, 'y': 71}, {'x': 161, 'y': 62}, {'x': 35, 'y': 273}, {'x': 76, 'y': 173}]
提交验证码...
提交结果: {'ok': True, 'picked': ['道', '往', '神', '海']}
重新请求数据...
数据请求结果: {'data': [894637, 734053, 270861, 282855, 326301, 205303, 891095, 636121, 123555, 775199]}
第2页数据: [894637, 734053, 270861, 282855, 326301, 205303, 891095, 636121, 123555, 775199]
===== 处理第3页 =====
识别结果: [['金', '8', '界'], ['昃', '紫', '张'], ['白', '灵', '4']]
目标文字: ['8', '紫', '界', '白']
目标位置: [(0, 1), (1, 1), (0, 2), (2, 0)]
点击坐标: [{'x': 179, 'y': 49}, {'x': 166, 'y': 118}, {'x': 255, 'y': 39}, {'x': 27, 'y': 234}]
提交验证码...
提交结果: {'ok': True, 'picked': ['8', '紫', '界', '白']}
重新请求数据...
数据请求结果: {'data': [760583, 856107, 453772, 623206, 358532, 710501, 666583, 356258, 865814, 436600]}
第3页数据: [760583, 856107, 453772, 623206, 358532, 710501, 666583, 356258, 865814, 436600]
===== 处理第4页 =====
识别结果: [['黄', '暑', '神'], ['道', '山', '问'], ['虚', '法', '土']]
目标文字: ['虚', '山', '暑', '神']
目标位置: [(2, 0), (1, 1), (0, 1), (0, 2)]
点击坐标: [{'x': 42, 'y': 253}, {'x': 131, 'y': 124}, {'x': 162, 'y': 63}, {'x': 258, 'y': 51}]
提交验证码...
提交结果: {'ok': True, 'picked': ['虚', '山', '暑', '神']}
重新请求数据...
数据请求结果: {'data': [749652, 839732, 925292, 580420, 116711, 499567, 374312, 370498, 942440, 183163]}
第4页数据: [749652, 839732, 925292, 580420, 116711, 499567, 374312, 370498, 942440, 183163]
===== 处理第5页 =====
识别结果: [['3', '问', '灵'], ['收', '玄', '火'], ['', '生', '黄']]
目标文字: ['玄', '生', '黄', '3']
目标位置: [(1, 1), (2, 1), (2, 2), (0, 0)]
点击坐标: [{'x': 146, 'y': 176}, {'x': 147, 'y': 262}, {'x': 223, 'y': 259}, {'x': 31, 'y': 64}]
提交验证码...
提交结果: {'ok': True, 'picked': ['玄', '生', '黄', '3']}
重新请求数据...
数据请求结果: {'data': [669166, 308018, 418604, 144588, 526130, 955683, 240565, 410165, 338604, 368598]}
第5页数据: [669166, 308018, 418604, 144588, 526130, 955683, 240565, 410165, 338604, 368598]
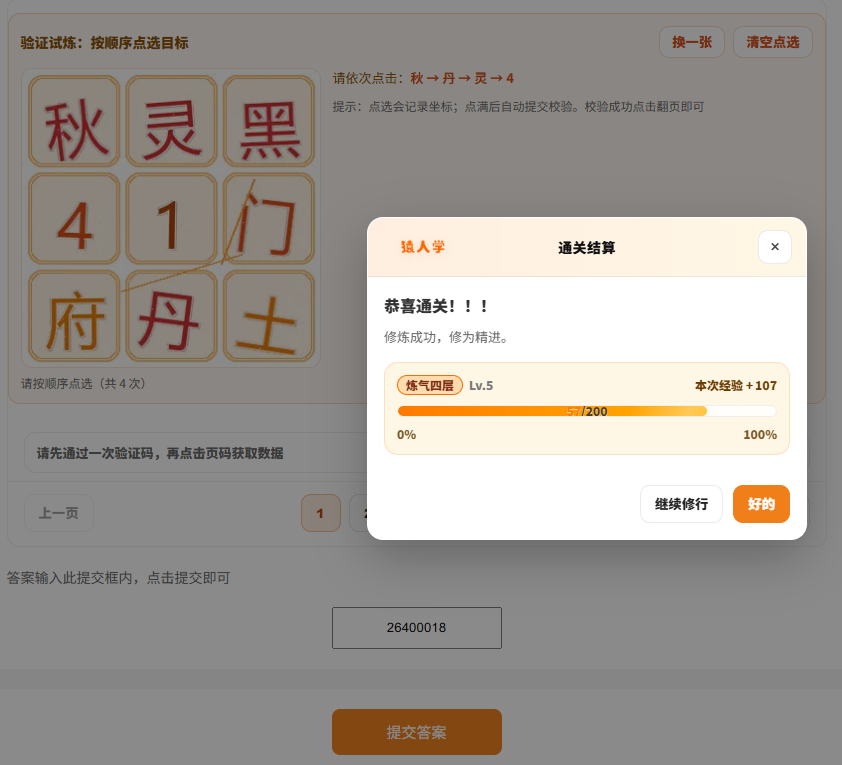
===== 计算结果 =====
所有数据的和: 26400018
然后提交
代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
猿人学第8题 验证码 图文点选 解决方案
功能:自动识别验证码,提交点击坐标,获取所有页数据并计算总和
"""
# 导入必要的库
import requests # 用于发送HTTP请求
import cv2 # 用于图像处理
import numpy as np # 用于数组操作
import time # 用于时间相关操作
from cnocr import CnOcr # 用于文字识别
import base64 # 用于处理base64编码的图片
from typing import Union, List, Tuple # 用于类型注解
# 配置信息
SESSION_KEY = '' # 猿人学会话密钥
PAGE = 1 # 起始页码
# API地址和参数
API_URL = "https://match.yuanrenxue.cn/api/question/8" # 数据接口
params = {
'page': PAGE, # 页码
'pageSize': 10 # 每页数据量
}
# 请求头
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36",
'Accept': "application/json, text/javascript, */*; q=0.01",
'sec-ch-ua-platform': "Windows",
'x-requested-with': "XMLHttpRequest",
'sec-ch-ua': "\"Google Chrome\";v=\"147\", \"Not.A/Brand\";v=\"8\", \"Chromium\";v=\"147\"",
'sec-ch-ua-mobile': "?0",
'sec-fetch-site': "same-origin",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
'referer': "https://match.yuanrenxue.cn/match/8",
'accept-language': "zh-CN,zh;q=0.9",
'priority': "u=1, i",
'Cookie': f"sessionid={SESSION_KEY}" # 使用配置的会话密钥
}
def get_captcha():
"""
获取验证码信息
返回:验证码的JSON响应
"""
captcha_url = 'https://match.yuanrenxue.cn/api2/8' # 验证码接口
captcha_params = {
't': str(int(time.time() * 1000)) # 添加时间戳,避免缓存
}
response = requests.get(
captcha_url, params=captcha_params, headers=headers)
return response.json()
def split_image_grid(img_input: Union[str, bytes, np.ndarray], grid: int = 3) -> Tuple[List[List[np.ndarray]], List[List[Tuple[int, int]]]]:
"""
将图片切分为 grid x grid 的二维数组
参数:
img_input: 图片输入(base64字符串、字节或numpy数组)
grid: 网格大小,默认为3
返回:
cells: 二维数组,存储每个网格的图片
positions: 二维数组,存储每个网格的中心点坐标
"""
# 解析图片
if isinstance(img_input, np.ndarray):
im = img_input
elif isinstance(img_input, bytes):
im = cv2.imdecode(np.frombuffer(img_input, np.uint8), cv2.IMREAD_COLOR)
elif isinstance(img_input, str):
if img_input.startswith("data:image"):
img_input = img_input.split(",")[1]
img_bytes = base64.b64decode(img_input)
im = cv2.imdecode(np.frombuffer(
img_bytes, np.uint8), cv2.IMREAD_COLOR)
elif len(img_input) > 100:
img_bytes = base64.b64decode(img_input)
im = cv2.imdecode(np.frombuffer(
img_bytes, np.uint8), cv2.IMREAD_COLOR)
else:
im = cv2.imread(img_input)
else:
raise ValueError("不支持的图片类型")
if im is None:
raise ValueError("图片解析失败")
# 处理图片尺寸
h, w = im.shape[:2]
h = (h // grid) * grid # 裁剪高度
w = (w // grid) * grid # 裁剪宽度
im = im[:h, :w] # 裁剪图片
cell_h = h // grid # 每个网格的高度
cell_w = w // grid # 每个网格的宽度
# 构建二维数组
cells = [] # 存储网格图片
positions = [] # 存储网格中心点坐标
for i in range(grid):
row_cells = [] # 当前行的网格图片
row_pos = [] # 当前行的网格坐标
for j in range(grid):
# 计算当前网格的坐标范围
y1 = i * cell_h
y2 = (i + 1) * cell_h
x1 = j * cell_w
x2 = (j + 1) * cell_w
# 提取当前网格
cell = im[y1:y2, x1:x2]
row_cells.append(cell)
# 计算中心点坐标
cx = int((x1 + x2) / 2)
cy = int((y1 + y2) / 2)
row_pos.append((cx, cy))
cells.append(row_cells)
positions.append(row_pos)
return cells, positions
def recognize_all_cells(cells):
"""
识别所有网格中的文字
参数:
cells: 二维数组,存储网格图片
返回:
recognized_texts: 二维数组,存储每个网格识别的文字
"""
# 初始化OCR
ocr = CnOcr(det_model_name='ppocr\\ch_PP-OCRv3_rec_infer.onnx',
det_model_backend='onnx')
recognized_texts = [] # 存储识别结果
# 识别每个网格
for row in cells:
row_texts = [] # 当前行的识别结果
for cell in row:
result = ocr.ocr(cell) # 识别文字
text = result[0]['text'] if result else '' # 提取文字
row_texts.append(text)
recognized_texts.append(row_texts)
return recognized_texts
def find_target_positions(recognized_texts, targets):
"""
找到所有目标文字在网格中的位置
参数:
recognized_texts: 二维数组,存储识别的文字
targets: 列表,存储目标文字
返回:
positions: 列表,存储目标文字的位置 (行, 列)
"""
positions = [] # 存储目标位置
# 查找每个目标文字
for target in targets:
for i, row in enumerate(recognized_texts):
for j, text in enumerate(row):
if text == target:
positions.append((i, j)) # 记录位置
break
else:
continue # 内循环未break,继续外循环
break # 找到目标,跳出外循环
return positions
def generate_random_coordinates(positions, cell_positions, cell_size=100):
"""
生成点击到目标文字的随机XY坐标数组
参数:
positions: 列表,存储目标位置
cell_positions: 二维数组,存储网格中心点坐标
cell_size: 网格大小,默认为100
返回:
coordinates: 列表,存储点击坐标 {"x": x, "y": y}
"""
coordinates = [] # 存储点击坐标
for pos in positions:
if not pos:
continue
row, col = pos
center_x, center_y = cell_positions[row][col] # 获取中心点坐标
# 生成围绕中心点的随机偏移
offset_x = np.random.randint(-cell_size//3, cell_size//3)
offset_y = np.random.randint(-cell_size//3, cell_size//3)
# 计算最终点击坐标
x = center_x + offset_x
y = center_y + offset_y
# 确保坐标在合理范围内
x = max(0, min(x, 3*cell_size))
y = max(0, min(y, 3*cell_size))
coordinates.append({"x": x, "y": y})
return coordinates
def submit_captcha(captcha_id, clicks):
"""
提交验证码
参数:
captcha_id: 验证码ID
clicks: 点击坐标数组
返回:
提交结果的JSON响应
"""
submit_url = 'https://match.yuanrenxue.cn/api2/8' # 提交接口
# 提交请求头
submit_headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/147.0.0.0 Safari/537.36",
'Accept': "application/json, text/javascript, */*; q=0.01",
'sec-ch-ua-platform': "Windows",
'x-requested-with': "XMLHttpRequest",
'sec-ch-ua': "\"Google Chrome\";v=\"147\", \"Not.A/Brand\";v=\"8\", \"Chromium\";v=\"147\"",
'content-type': "application/x-www-form-urlencoded; charset=UTF-8",
'sec-ch-ua-mobile': "?0",
'origin': "https://match.yuanrenxue.cn",
'sec-fetch-site': "same-origin",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
'referer': "https://match.yuanrenxue.cn/match/8",
'accept-language': "zh-CN,zh;q=0.9",
'priority': "u=1, i",
'Cookie': f"sessionid={SESSION_KEY}"
}
# 提交数据
submit_data = {
'captcha_id': captcha_id,
'clicks': str(clicks).replace("'", '"') # 转换为JSON格式字符串
}
# 发送请求
response = requests.post(
submit_url, headers=submit_headers, data=submit_data)
return response.json()
# 主函数
def main():
"""
主函数:处理所有页面的数据获取和验证码
"""
all_data = [] # 存储所有页面的数据
# 处理1-5页数据
for i in range(PAGE, 6):
print(f"\n===== 处理第{i}页 =====")
# 更新页码参数
params['page'] = i
# 第5页使用特定的User-Agent
if i == 5:
headers['User-Agent'] = 'yuanrenxue'
# 请求数据
response = requests.get(API_URL, params=params, headers=headers).json()
# 处理验证码
if response.get('action', '') == 'captcha':
max_retries = 3 # 最大重试次数
retry_count = 0 # 当前重试次数
while retry_count < max_retries:
# 获取验证码
captcha = get_captcha()
image_base64 = captcha.get('image', '')
targets = captcha.get('targets', [])
image_w = captcha.get('w', '')
image_id = captcha.get('id', '')
# 拆分图片
cells, cell_positions = split_image_grid(image_base64, 3)
# 识别文字
recognized_texts = recognize_all_cells(cells)
print("识别结果:", recognized_texts)
print("目标文字:", targets)
# 找到目标位置
target_positions = find_target_positions(
recognized_texts, targets)
print("目标位置:", target_positions)
# 检查是否找到至少4个目标
if len(target_positions) >= 4:
# 只取前4个目标
target_positions = target_positions[:4]
# 生成点击坐标
cell_size = image_w // 3
click_coords = generate_random_coordinates(
target_positions, cell_positions, cell_size)
print("点击坐标:", click_coords)
# 提交验证码
print("提交验证码...")
submit_result = submit_captcha(image_id, click_coords)
print("提交结果:", submit_result)
# 检查提交结果
if submit_result.get('ok', False):
# 重新请求数据
print("重新请求数据...")
response = requests.get(
API_URL, params=params, headers=headers).json()
print("数据请求结果:", response)
break
else:
print(
f"验证码提交失败: {submit_result.get('msg', 'Unknown error')}")
retry_count += 1
time.sleep(1) # 等待1秒后重试
else:
print(
f"识别不完整,只找到{len(target_positions)}个目标文字,需要至少4个,重新请求识别...")
retry_count += 1
time.sleep(1) # 等待1秒后重试
# 处理数据
if 'data' in response:
print(f"第{i}页数据:", response['data'])
all_data.extend(response['data']) # 添加到总数据列表
else:
print(f"第{i}页数据获取失败,程序退出!")
exit()
# 等待2秒,避免请求过于频繁
time.sleep(2)
# 计算并输出总和
if all_data:
total_sum = sum(all_data)
print(f"\n===== 计算结果 =====")
print(f"所有数据的和: {total_sum}")
else:
print("\n未获取到任何数据")
# 执行主函数
if __name__ == "__main__":
main()

 [复制链接]
[复制链接]
 发表于 2026-4-24 22:21
发表于 2026-4-24 22:21
 |
发表于 2026-4-28 21:47
|
发表于 2026-4-28 21:47



