好友 阅读权限 80
听众 最后登录 1970-1-1
烟99
发表于 2024-10-30 17:24
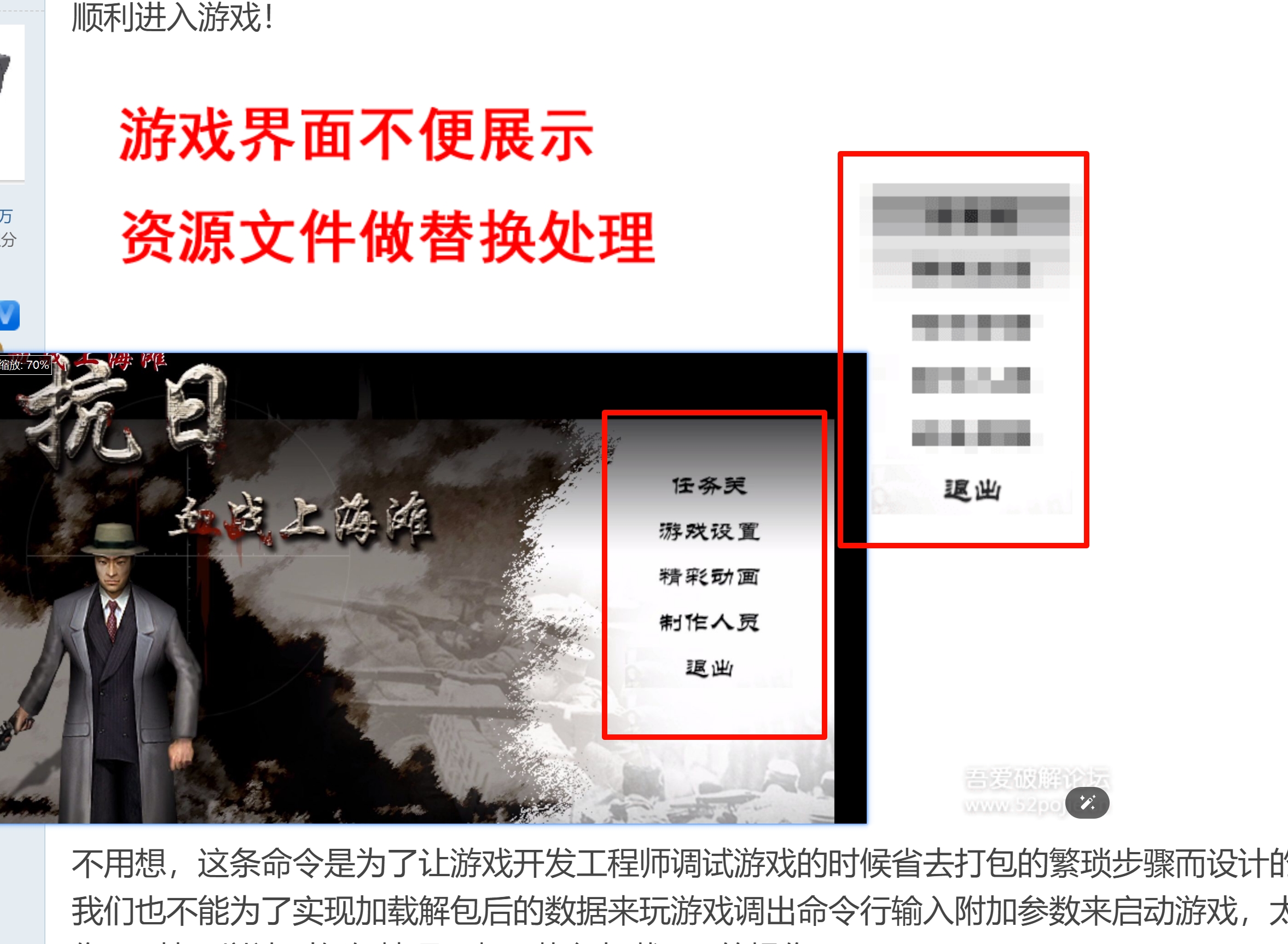
本帖最后由 烟99 于 2025-1-2 22:14 编辑 本帖不反对转载,但是转载请注明出处及本帖链接,谢谢! 首先特别鸣谢版主@爱飞的猫 在我的另一篇分析帖 中提供了分析思路,今天就学以致用,举一反三,分析一下其他游戏。 本文仅限技术交流和软件安全性评估,游戏资源文件版权归游戏公司所有,切勿用于非法目的!因而造成的一切后果概不负责! 20年前的一个暑假,我的父亲像平常一样下班回到家。我看到父亲提着一个纸袋,好奇地问:“爸爸,这里面是什么东西啊?”父亲从纸袋里拿出一个软件盒子,盒子上印着100年前的中国,一位中国战士在华东地区重要城市英勇抗击敌人的画面。父亲说:“给你,快打开放到电脑光驱里安装吧,这是从同事那儿借来的枪战游戏。”接着,父亲又递给我一张纸条,告诉我这是游戏的作弊码,要想看剧情但是卡关了就用作弊码。我启动了游戏,里面逼真的场景、激烈的交火画面,尤其是启用作弊码后能够零伤害杀敌,这让9岁的我感到无比快乐,无限释放释放多巴胺,这一切都深深地烙印在我的记忆里,终生难忘……《吾爱记账号》 ,其中账号数据的存储层就用到了文件首尾特征字符+Zlib压缩的存储方案,这也是现在市面上的应用软件最常用的压缩算法之一。破解 版软件的打击力度的持续加大,再加上这款游戏年代久远,很多下载站已经把下载链接删除了,找的我好艰辛。最终,我从某云游戏平台的云电脑上预装的单机游戏提取到了游戏本体,打包压缩,用微信传回自己的电脑。
[C#] 纯文本查看 复制代码
using Ionic.Zlib;// 此为第三方NuGet包DotNetZip的引用,请自行安装
using System.IO;
namespace UnZlib
{
internal static class Program
{
/// <summary>
/// 程序主函数
/// </summary>
static void Main()
{
// 输入和输出文件名
string infilePath = "Untitled1.bin";
string outfilePath = Path.GetFileName(infilePath)+ "_Decompresed"+Path.GetExtension(infilePath);
// 将欲解压的文件载入到字节集数组
byte[] inputByte = File.ReadAllBytes(infilePath);
// 调用Zlib并解压数据
byte[] outputByte = Zlib.DeZlibcompress(inputByte);
// 写到文件
File.WriteAllBytes(outfilePath, outputByte);
}
/// <summary>
/// Zlib操作类(本文章只涉及解压,压缩操作略)
/// </summary>
public static class Zlib
{
/// <summary>
/// Zlib解压缩
/// </summary>
/// <param name="data"></param>
/// <returns></returns>
public static byte[] DeZlibcompress(byte[] data)
{
// 创建数据输入流和输出流
using (var compressedInput = new MemoryStream(data))
using (var decompressedOutput = new MemoryStream())
{
// 执行解压操作
using (var decompressor = new ZlibStream(compressedInput, Ionic.Zlib.CompressionMode.Decompress))
{
decompressor.CopyTo(decompressedOutput);
}
//返回已处理的数据
return decompressedOutput.ToArray();
}
}
}
}
}
编写后,运行,生成了文件Untitled1_Decompresed.bin
将这个文件拖入到010 Editor。我们看到,解压后文件的Hex内容已经不是那么杂乱无章的了,很有顺序。显然,这大概率是一个图像文件,我们尝试修改拓展名为JPG,并使用图片浏览器来查看。
这四个字节记录数据方法为从右往左的方向进行记录,因此,我们将这种记录方式称为『低位编址(little endian) 』。
一条文件信息由五个部分组成
文件目录区和压缩方式我们搞清楚了,但是还有两个棘手的问题:数据区到底多长?文件数量到底多少个?不知道数据区或者文件目录区的大小,无法定位目录区的字节地址,不知道文件数量,批量解压操作的for循环次数不知道写多少,这两个问题不解决,我们只能解出无目录和文件名的文件。所以还要到文件尾部寻找线索。
文件数量为1733
由于BitConverter方法要求数据必须是八字节,我们还不能提前拷贝,这样的话把与操作无关的其他字节也拷进去了,所有要拷完后补四个00,鉴于该操作比较多,先封装到一个函数中 [C#] 纯文本查看 复制代码
using System;
using System.Reflection;
namespace PCKExtractetor
{
/// <summary>
/// 公共函数
/// </summary>
internal class PublicFunction
{
/// <summary>
/// <字节集型> 8字节补零
/// <param name="bytes">(字节集 欲填充0x00的8字节字节集数组)</param>
/// <returns><para>返回处理后的8字节数组</para></returns>
/// </summary>
public static byte[] EightByteConverter(byte[] bytes)
{
// 补到8字节用于Bit转换
byte[] newByees = new byte[8];
Array.Copy(bytes, 0, newByees, 0, bytes.Length);
for (int i = bytes.Length; i < 8; i++)
{
newByees[i] = 0x00; // 补充0x00
}
// 将处理完的字节集数组交还给bytes变量
return newByees;
}
}
}
随后引入第三方NuGet包DotNetZip,这是解压PCK数据的必备类库,下方代码是实现解压缩功能的核心代码 [C#] 纯文本查看 复制代码
using Ionic.Zlib;
using System.IO;
using System.Security.Cryptography;
namespace PCKExtractetor
{
/// <summary>
/// Zlib类
/// </summary>
internal class ZLibHelper
{
/// <summary>
/// <字节集型> 使用Zlib算法压缩数据到字节数组
/// <param name="data">(字节集型 要压缩的数据 ,</param>
/// <returns>成功返回压缩后的字节集数组,失败返回NULL。</returns>
/// </summary>
public static byte[] ZlibCompress(byte[] data)
{
byte[] ReturnData;
//进行Zlib压缩
using (var input = new MemoryStream(data))
using (var output = new MemoryStream())
{
using (var compressor = new ZlibStream(output, Ionic.Zlib.CompressionMode.Compress))
{
input.CopyTo(compressor);
}
ReturnData = output.ToArray();
return ReturnData;
}
}
/// <summary>
/// <字节集型> 使用Zlib算法解压缩数据到字节数组
/// <param name="data">(字节集型 欲解要压缩的数据 ,</param>
/// <returns>成功返回压缩后的字节集数组,失败返回NULL。</returns>
/// </summary>
public static byte[] DeZlibcompress(byte[] data)
{
using (var compressedInput = new MemoryStream(data))
using (var decompressedOutput = new MemoryStream())
{
using (var decompressor = new ZlibStream(compressedInput, Ionic.Zlib.CompressionMode.Decompress))
{
decompressor.CopyTo(decompressedOutput);
}
//返回已处理的数据
return decompressedOutput.ToArray();
}
}
}
}
最后是PCK解压代码,分三个部分,第一部分为文件列表获取,第二部分为按文件顺序号单独解压文件,第三部分为解压全部文件 [C#] 纯文本查看 复制代码
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
using System.Threading.Tasks;
/*
* PCK解压算法代码
* 注意事项:
* 1、本代码使用了C#的五元组,故目标框架必须使用.NetFramework4.5及以上的版本,否则会认定语法错误
* 2、必须使用第三方NuGet包DotNetZip,否则Zlib数据无法操作
*
* 解压流程简述:
* 取PCK数据区大小→取PCK内部文件的总数量→取内部文件目录区每个文件的偏移、大小等信息→开始解压
*
* 本代码版权归吾爱破解@烟99所有,转载请注明出处,谢谢!
*/
namespace PCKExtractetor
{
/// <summary>
/// PCK解压操作类
/// </summary>
internal class PCKExtractetor
{
/// <summary>
/// <五元List> 取PCK内部文件列表
/// <param name="pckfilePath">(文本型 欲获取内部文件列表的PCK文件) </param>
/// <returns><para>成功返回PCK文件的单个文件的目录长度、完整文件路径、、文件偏移、实际大小、压缩大小,并封装在 <List>中</para></returns>
/// </summary>
public static List<Tuple<int, string, long, long, long>> GetPCKInformation(string pckfilePath)
{
// 定义一个五元组的<List>,用于返回文件信息,Tuple元素内容依次为:文件路径长度,文件路径,文件偏移,文件真实大小,文件物理大小
List<Tuple<int, string, long, long, long>> returnList = new List<Tuple<int, string, long, long, long>>();
// 取PACK文件大小
FileInfo fileInfo = new FileInfo(pckfilePath);
long pckfileSize = fileInfo.Length;
// 调试输出PCK文件大小
Console.WriteLine("PCK文件大小:" + fileInfo.Length + " 字节(十六进制:" + fileInfo.Length.ToString("X") + ")");
// 定义PCK文件特征区大小
long pckSignatureSize = 272;
// 开始解析文件
using (FileStream fs = new FileStream(pckfilePath, FileMode.Open))
{
// 处理数据区物理大小
byte[] dataSizeBit = new byte[4]; // 字节集状态下的数据区物理大小数值
long dataSize; // 长整型的数据区物理大小数值
// 定位到文件长度减去PCK文件特征区大小再减去4个字节的位置
fs.Seek(pckfileSize - pckSignatureSize + 4, SeekOrigin.Begin);
// 取数据区物理大小数值信息
fs.Read(dataSizeBit, 0, dataSizeBit.Length);
// 将取到的物理大小数值信息补满八字节,然后转换成长整型数值
dataSize = BitConverter.ToInt64(PublicFunction.EightByteConverter(dataSizeBit), 0);
// 调试输出数据区物理大小
Console.WriteLine("该文件的数据区物理大小为 " + dataSize.ToString() + " 字节(十六进制:" + dataSize.ToString("X") + ")");
// 处理PCK内部文件文件数量
byte[] fileCountBit = new byte[4]; // 字节集状态下的数据区物理大小数值
long fileCount; // 长整型的数据区物理大小数值
// 定位到文件长度减去PCK文件特征区大小的位置
fs.Seek(pckfileSize - 8, SeekOrigin.Begin);
// 取PCK内部文件数量信息
fs.Read(fileCountBit, 0, fileCountBit.Length);
// 将取到的PCK内部文件信息补满八字节,然后转换成长整型数值
fileCount = BitConverter.ToInt64(PublicFunction.EightByteConverter(fileCountBit), 0);
// 调试输出包内文件数量
Console.WriteLine("该PCK文件包应有 " + fileCount.ToString() + " 个文件(十六进制:" + fileCount.ToString("X") + ")");
// 开始处理目录区
byte[] fileIdxByte = new byte[pckfileSize - dataSize - pckSignatureSize]; // 文件索引数据
// 定位到文件索引区的首个字节,即数据区物理大小的值
fs.Seek(dataSize, SeekOrigin.Begin);
// 开始填充文件索引数据
fs.Read(fileIdxByte, 0, fileIdxByte.Length);
// 调试输出文件索引数据大小
Console.WriteLine("该PCK文件包的文件索引大小为 " + fileIdxByte.Length.ToString() + " 字节(十六进制:" + fileIdxByte.Length.ToString("X") + ")");
// 开始创建文件列表
int byteOffset = 0; //字节偏移记录
// 开始for循环,循环次数为文件数量
for (int i = 0; i < fileCount; i++)
{
// 取文件目录文本长度
byte[] filePathLengthBit = new byte[4];
// 从当前偏移位置开始拷贝四个字节
Array.Copy(fileIdxByte, byteOffset, filePathLengthBit, 0, filePathLengthBit.Length);
// 四字节补到八字节,再转换成整型数值,因为所有目录文本字节后面都填充了一个00,因此先减去1,后续再补上
int filePathLength = BitConverter.ToInt32(PublicFunction.EightByteConverter(filePathLengthBit), 0) - 1;
//字节偏移移到目录的第一个字符
byteOffset += 4;
// 取文件目录
byte[] filePathStringBit = new byte[filePathLength];
// 从当前的字节偏移位置拷贝文件目录文本字节数据,文本长度变量filePathLength来决定
Array.Copy(fileIdxByte, byteOffset, filePathStringBit, 0, filePathLength);
// 将文件目录文本字节数据转换为文本型数据
string filePathString = Encoding.Default.GetString(filePathStringBit);
//字节偏移移到当前文件偏移的字节,由于刚才目录长度被减掉了1,所以要补回来
byteOffset += filePathLength + 1;
// 取文件偏移
byte[] fileOffsetBit = new byte[4];
// 从当前偏移位置开始拷贝四个字节
Array.Copy(fileIdxByte, byteOffset, fileOffsetBit, 0, fileOffsetBit.Length);
// 四字节补到八字节,再转换成长整型数值,
long fileOffset = BitConverter.ToInt64(PublicFunction.EightByteConverter(fileOffsetBit), 0);
//字节偏移到文件实际大小的字节
byteOffset += 4;
// 取文件实际大小
byte[] fileActualsizeBit = new byte[4];
// 从当前偏移位置开始拷贝四个字节
Array.Copy(fileIdxByte, byteOffset, fileActualsizeBit, 0, fileActualsizeBit.Length);
// 四字节补到八字节,再转换成长整型数值,
long fileActualsize = BitConverter.ToInt64(PublicFunction.EightByteConverter(fileActualsizeBit), 0);
//字节偏移到文件压缩后大小的字节
byteOffset += 4;
// 取文件压缩大小
byte[] filecompressionsizeBit = new byte[4];
// 从当前偏移位置开始拷贝四个字节
Array.Copy(fileIdxByte, byteOffset, filecompressionsizeBit, 0, filecompressionsizeBit.Length);
// 四字节补到八字节,再转换成长整型数值,
long filecompressionsize = BitConverter.ToInt64(PublicFunction.EightByteConverter(filecompressionsizeBit), 0);
//字节偏移到下一个文件长度信息字节,为下一次循环做准备
byteOffset += 4;
// 将获取到的信息添加到五元组的<List>returnList
returnList.Add(Tuple.Create(filePathLength, filePathString, fileOffset, fileActualsize, filecompressionsize));
}
// 关掉文件流以节约内存
fs.Close();
}
// 循环结束将五元组的<List>returnList返回
return returnList;
}
/// <summary>
/// 解压单独文件
/// <param name="pckfilePath">(文本型 欲单独解压的PCK文件, </param>
/// <param name="fileList">List 已处理好的文件列表, </param>
/// <param name="targetNum">欲解压的文件顺序号, </param>
/// <param name="savePath">欲保存的路径)</param>
/// </summary>
public static void ExtractFileSingle(string pckfilePath, List<Tuple<int, string, long, long, long>> fileList, int targetNum, string savePath)
{
// 取单独的文件名
string fileName = Path.GetFileName(fileList[targetNum].Item2);
// 开始获取指定文件的物理数据
long pckOffset = fileList[targetNum].Item3; //PCK文件偏移
long actualDataSize = fileList[targetNum].Item4; // 指定文件的真实大小
long compressionDataSize = fileList[targetNum].Item5; // 指定文件的物理大小
byte[] actualData; // 指定文件的实际大小数据字节集数组
byte[] compressionData = new byte[compressionDataSize]; // 指定文件的物理大小数据字节集数组
// 将物理数据拷贝到文件的物理数据字节集数组中
using (FileStream fs = new FileStream(pckfilePath, FileMode.Open))
{
fs.Seek(pckOffset, SeekOrigin.Begin);
fs.Read(compressionData, 0, (int)compressionDataSize);
// 由于极少数文件未压缩,将导致ZLib抛出数据无法识别的异常,因此需要加判断,判断依据为检查压缩前后大小
if (actualDataSize == compressionDataSize)
{
actualData = compressionData;
}
else
{
actualData = ZLibHelper.DeZlibcompress(compressionData);
}
File.WriteAllBytes(savePath, actualData);
// 关掉文件流以节约内存
fs.Close();
}
}
/// <summary>
/// 解压所有文件
/// <param name="pckfilePath">(文本型 欲单解压的PCK文件, </param>
/// <param name="fileList">List 已处理好的文件列表, </param>
/// <param name="savePath">欲保存的路径)</param>
/// </summary>
public static void ExtractAllFile(string pckfilePath, List<Tuple<int, string, long, long, long>> fileList, string savePath)
{
// 取文件数量,即List成员数
int fileCount = fileList.Count;
// 设置解压文件夹,保存到文件名+_PCKUnpacked中
string extractFolder = Path.GetFileNameWithoutExtension(pckfilePath) + "_PCKUnpacked";
Directory.CreateDirectory(extractFolder);
//开始解压操作
using (FileStream fs = new FileStream(pckfilePath, FileMode.Open))
{
// 进入for循环
for (int i = 0; i < fileCount; i++)
{
// 取文件名和文件路径
string filePath = fileList[i].Item2;
string fileDir = Path.GetDirectoryName(filePath);
string fileName = Path.GetFileName(filePath);
// 置该文件最终绝对路径
string finalPath = savePath + "\\" + extractFolder + "\\" + filePath;
long pckOffset = fileList[i].Item3; //PCK文件偏移
long actualDataSize = fileList[i].Item4; // 指定文件的真实大小
long compressionDataSize = fileList[i].Item5; // 指定文件的物理大小
byte[] actualData; // 指定文件的物理数据字节集数组
byte[] compressionData = new byte[compressionDataSize]; // 指定文件的物理数据字节集数组
fs.Seek(pckOffset, SeekOrigin.Begin);
fs.Read(compressionData, 0, (int)compressionDataSize);
// 由于极少数文件未压缩,将导致ZLib抛出数据无法识别的异常,因此需要加判断,判断依据为检查压缩前后大小
if (actualDataSize == compressionDataSize)
{
actualData = compressionData;
}
else
{
actualData = ZLibHelper.DeZlibcompress(compressionData);
}
// 检查目录是否存在,不存在则创建
if (!Directory.Exists(Path.GetDirectoryName(finalPath)))
{
Directory.CreateDirectory(Path.GetDirectoryName(finalPath));
}
// 此轮工作已结束,写到文件
File.WriteAllBytes(finalPath, actualData);
}
// 关掉文件流以节约内存
fs.Close();
}
}
}
}
GUI程序源码就不放了,论坛禁止发布破解相关的成品,大家根据上面的代码基本上都能顺利解包。 为了保证数据能正确的解压,原则上应该加一个文件特征区的验证,以确保不是这款游戏的PCK不能加载,但是没有写,但其实写法很简单,就是用文件流把特征区的签名读成Byte字节集数组,然后进行比对,比对结果不通过则抛出异常,大家本着这个思路去写,我就不举例子了。 本来到这里文章应该要结束的,但是有些同学想知道游戏能不能加载解包后的数据?
[Asm] 纯文本查看 复制代码
jz short loc_41ECA8
最后说说如何学好游戏资源文件逆向吧,说说我的经验 其次,要会汇编语言,还要会用IDE、OD等常用的分析工具,因为很多游戏的Pack文件的字节是经过异或运算的,需要通过跑EXE,下断点来确定数据处理流程,一些加壳的有混淆的还要掌握脱壳 技术。 还有一点,就是多看别人的案例,你会发现各大游戏厂商的Pack加密方式形形色色。 最后,就是要善用AI,因为无论是搜文件头部特征的资料亦或是代码查错亦或是分析思路,AI能够帮你回答。 以上是给初学者的建议,大家可以根据自己的学习习惯来酌情制定方案。 以上就是对这款游戏PCK资源文件的分析,文章结束 Thank you for reading! 2024.11.15更新 解包代码进行了优化调整,优化了文件流处理方式,追加了PCK特征识别机制,由于之前读取文件目录偏移的时候是整体减去1,风险太大,故改为从byte里减1,更新代码请移步: https://www.52pojie.cn/thread-1983120-1-1.html 最后给大家个留个课后作业
课后作业答案揭晓: https://www.52pojie.cn/thread-1977704-1-1.html 参考资料:https://blog.csdn.net/u011149152/article/details/139168143 https://www.cnblogs.com/ainsliaea/p/15780903.html https://blog.csdn.net/weixin_51304981/article/details/126492628 https://blog.csdn.net/luxiaol/article/details/134921043
查看全部评分


 [复制链接]
[复制链接]
 发表于 2024-10-30 17:24
发表于 2024-10-30 17:24
 发表于 2024-11-3 23:31
发表于 2024-11-3 23:31
 |
发表于 2024-10-30 17:34
|
发表于 2024-10-30 17:34