[Python] 纯文本查看 复制代码 import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import os
ua = UserAgent().random
headers = {'User-Agent': ua,
'Host': 'demo.cndzq.com',
'Referer': 'https://lifesea.org/',
}
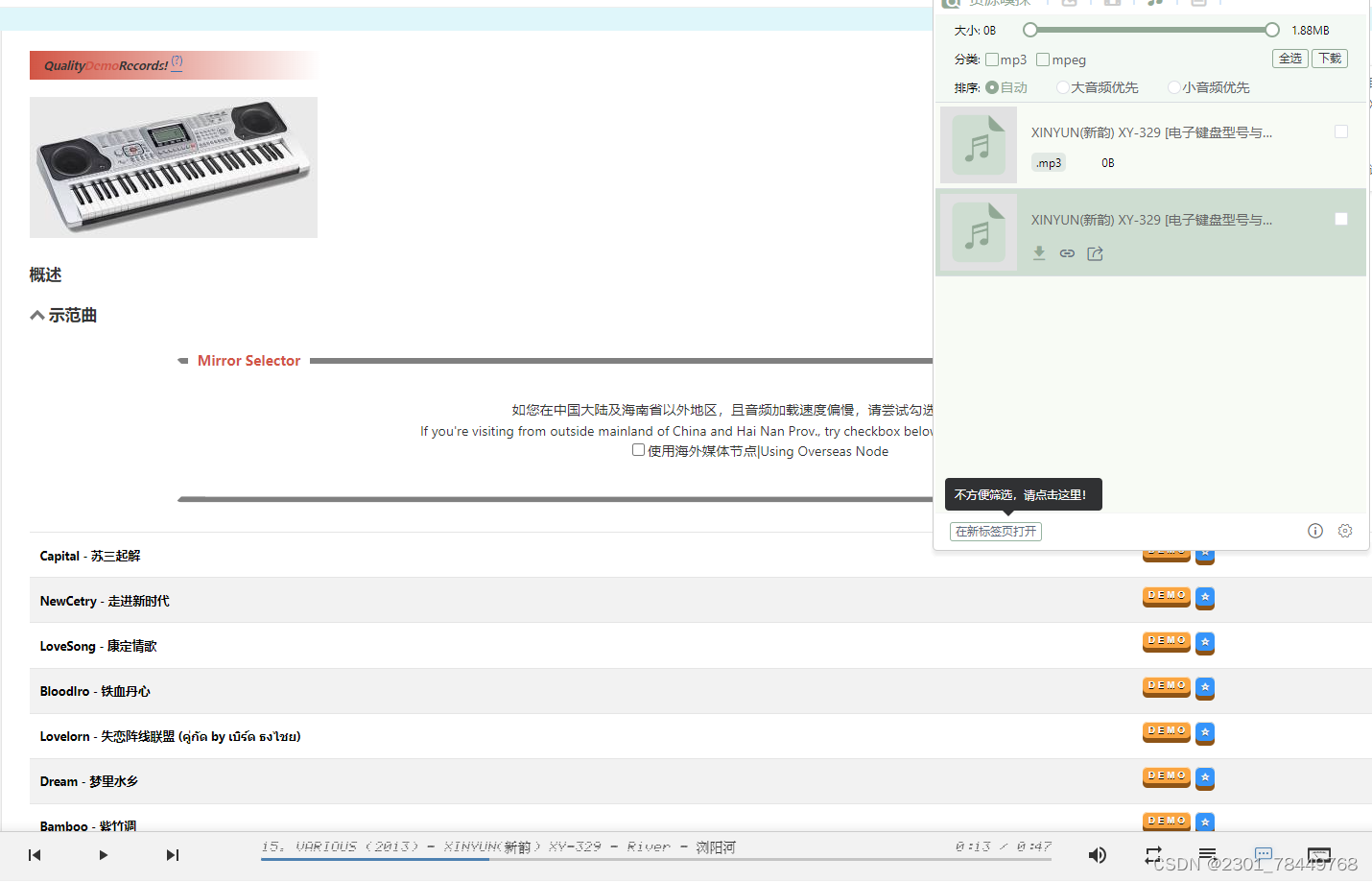
url = 'https://lifesea.org/keyboard/other/jiexi_collection/xinyun/xinyun_xy-329?pos=3'
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content.decode('utf-8'), 'html.parser').find('div', class_='table sectionedit4')
# print(soup.findAll('tr'))
path = '下载'
if not os.path.exists(path):
os.makedirs(path)
for i in soup.findAll('tr'):
aa = i.find('th', class_='col0')
if aa.find('a', class_='wikilink1'):
title = aa.text.split('-')[0] + '- ' + aa.find('a', class_='wikilink1').text
else:
title = aa.text
mp3_u = i.find('source').get('src')
con = requests.get(mp3_u, headers=headers)
with open(f'{path}/{title}.mp3', 'wb') as f:
f.write(con.content) | 
 [复制链接]
[复制链接]
 发表于 2024-8-5 23:55
发表于 2024-8-5 23:55