本帖最后由 ZDavy 于 2022-12-3 12:58 编辑
半自动化给PDF加书签、目录-Python实现-可双击执行-上篇
2022年11月22日更新 v0.60
下载链接:https://github.com/Davy-Zhou/pdf_add_bookmark_semi/releases/download/v0.60/pdf_add_bookmark_semi.v0.60.zip
如果觉得好用请Star:https://github.com/Davy-Zhou/pdf_add_bookmark_semi
针对页偏移无法识别时,增加页偏移输入选项,无需重开程序
针对多个PDF要加书签情况,完成一个PDF加书签后,无需重开,回车即可给下一个PDF加书签
书签格式化库规则更新
新更新:新增自动化获取书签和识别PDF页偏移功能,v0.51

链接:https://github.com/Davy-Zhou/pdf_add_bookmark_semi/releases/tag/v0.51
https://davy.lanzoub.com/b011viwih
密码:9hl7
本工具用途,可用于给没有书签的PDF加书签,主要应用于扫描版PDF,工具主要实现是格式化书签和加书签,
书签获取需要配合其它的软件,后期会考虑尽量在获取书签时自动化,页偏移部分也可自动化,格式化规则库
也会按大家的需求更新,当然也可自已加。完整的博客截图放在最后面了,图片大多了,真传不过来。

工具界面
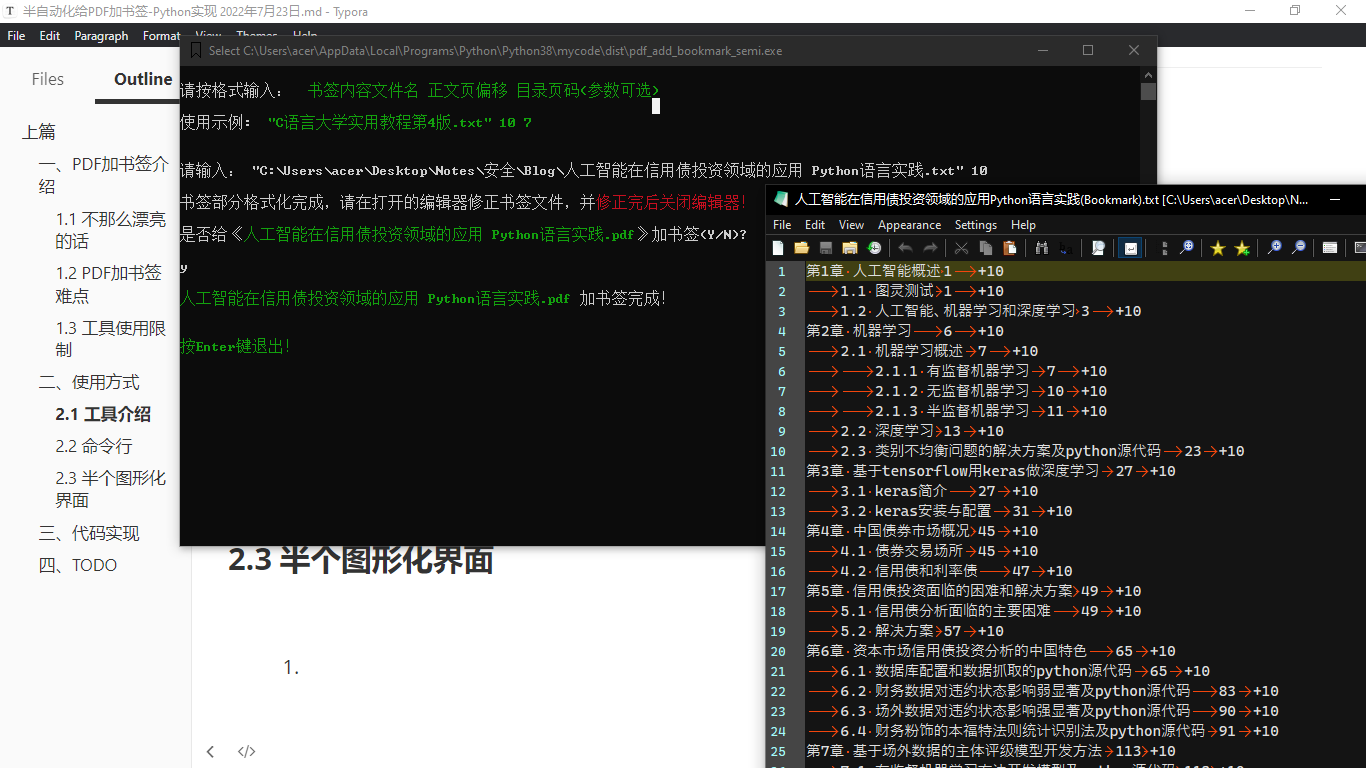
加了书签的示例

先前加书签的使用效果:https://www.52pojie.cn/thread-1665120-1-1.html
后面的部分,转成PDF放到网盘链接里面了
我把整个PDF转成图片了,看一下最后的图片,包含全部内容
如果访问不了,github也传了一份: https://github.com/Davy-Zhou/pdf_add_bookmark_semi
完整博客截图,github上也传了代码
# format_bookmark.py
[Python] 纯文本查看 复制代码 import subprocess
import re
import sys
#import os
from yaml import safe_load
from chardet import detect
# example
# input: python duxiu_regex.py C语言大学实用教程第4版.txt 17 12
# 3个参数 书签内容文件名 正文页偏移 目录页码
def format_bookmark():
config_path=sys.argv[0]
txt_filename=sys.argv[1]
page_offset_number=sys.argv[2]
if len(sys.argv)==4 :
directory_number=sys.argv[3]
# print('打开config.yaml','\n')
# input('调试\n')
with open(config_path+'\\Config\\config.yaml','r',encoding='utf-8') as f:
# print(config_path+'\\Config\\config.yaml'+'\n')
# input('调试\n')
config=safe_load(f)
# 检测编码GB18030、utf-8
with open(txt_filename,'rb') as f:
data = f.read()
file_encoding = detect(data)['encoding']
with open(str(txt_filename), 'r', encoding=file_encoding, errors = 'ignore') as f:
str_list = f.read()
# 书签格式化
for i in range(len(config['rules'])) :
for j in range(len(config['rules'][i]['rule'])):
regex_search=config['rules'][i]['rule'][j]['regex_search']
regex_repalce=config['rules'][i]['rule'][j]['regex_repalce']
if config['rules'][i]['rule'][j]['loaded'] and regex_search!=None and regex_repalce!=None:
regex_compiled = re.compile(regex_search, re.M)
str_list_re = regex_compiled.sub(regex_repalce, str_list)
str_list = str_list_re
# 加页偏移,后面有页偏移是动态变量加不进yaml
regex_page_offset = re.compile(r'(\d+)$', re.M)
str_list = regex_page_offset.sub(r'\1\t+'+str(page_offset_number),str_list)
# 路径保留空格
filename=str(txt_filename).split('\\')[-1]
path_name=str(txt_filename).split(filename)[0]
# 文件名去空格?
add_bookmark_filename = path_name+filename.replace(' ', '').split(
'.txt')[0]+r"(Bookmark)"+"."+filename.replace(' ', '').split('.')[-1]
with open(add_bookmark_filename, 'w+', encoding='utf-8-sig') as fw:
if len(sys.argv) == 4:
if config['first_letter_lower']:
fw.write('目录\t'+str(directory_number)+'\n'+str_list.lower())
else:
fw.write('目录\t'+str(directory_number)+'\n'+str_list)
elif len(sys.argv)==3:
if config['first_letter_lower']:
fw.write(str_list.lower())
else:
fw.write(str_list)
# 初次格式化完书签,再次使用Notepad3编辑修正
print("\n书签部分格式化完成,请在打开的编辑器修正书签文件,并\033[0;31;40m修正完后关闭编辑器!\033[0m\n")
if config['enable_editor']:
editor_path=(config['editor_path'] if ':' in config['editor_path'] else config_path+config['editor_path'])
subprocess.run([editor_path,add_bookmark_filename])
if __name__ == "__main__":
format_bookmark()
#pdf_add_bookmark_semi.py
[Python] 纯文本查看 复制代码 import sys
import format_bookmark as fbk
from pikepdf import Pdf, OutlineItem
from colorama import init
import os
def pike_add_bookmark():
txt_filename=sys.argv[1]
pdf_name = str(txt_filename).split('.txt')[0]+"."+"pdf"
filename=str(txt_filename).split('\\')[-1]
path_name=str(txt_filename).split(filename)[0]
bookmark_filename = path_name+filename.replace(' ', '').split(
'.txt')[0]+r"(Bookmark)"+"."+filename.replace(' ', '').split('.')[-1]
with Pdf.open(pdf_name,allow_overwriting_input=True) as pdf:
with pdf.open_outline() as outline:
outline.root.clear() # 清空原PDF书签
with open(bookmark_filename, 'r', encoding='utf-8-sig') as fb:
for line in fb.readlines():
txt_line = line.split('\t')
offset=''
if len(txt_line)>1:
offset = ((int(txt_line[-2]) + int(txt_line[-1]))
if txt_line[-2].isdigit() else int(txt_line[-1]))-1
# 一级书签
# Page counts are zero-based
if txt_line[0] != '':
L1_item = OutlineItem(txt_line[0], offset)
outline.root.append(L1_item)
# 二级书签
elif txt_line[1] != '':
L2_item = OutlineItem(txt_line[1], offset)
L1_item.children.append(L2_item)
# 三级书签
elif txt_line[2] != '':
L3_item = OutlineItem(txt_line[2], offset)
L2_item.children.append(L3_item)
# 四级书签
elif txt_line[3] != '':
L4_item = OutlineItem(txt_line[3], offset)
L3_item.children.append(L4_item)
pdf.save(pdf_name)
if __name__ == "__main__":
# 方便双击使用
init()
if len(sys.argv)==1:
print("\n请按格式输入: \033[0;32;40m书签内容文件名 正文页偏移 目录页码(参数可选)\033[0m\n")
print("使用示例: \033[0;32;40m\"C语言大学实用教程第4版.txt\" 10 7 \033[0m\n\n")
params =input("请输入: ").split('\"')
# print(params,'\n')
# input('调试\n')
py_dirname, py_name = os.path.split(os.path.abspath(sys.argv[0]))
sys.argv.clear()
sys.argv.extend([py_dirname])
sys.argv.extend([params[1]])
sys.argv.extend(params[-1].split())
# print(sys.argv,'\n')
# input('调试\n')
else:
py_dirname, py_name = os.path.split(os.path.abspath(sys.argv[0]))
sys.argv[0]=py_dirname
filename=str(sys.argv[1]).split('\\')[-1].replace('txt','pdf')
# print(filename,'\n')
# input('调试\n')
if len(sys.argv)<3 :
print("\n错误:参数不足\n使用示例: \"C语言大学实用教程第4版.txt\" 17 12\n或者: \"C语言大学实用教程第4版.txt\" 17\n")
sys.exit()
# print('进入format_bookmark','\n')
# input('调试\n')
fbk.format_bookmark()
print("是否给《\033[0;32;40m"+filename+"\033[0m》加书签(Y/N)?\n")
is_add_Bookmark=input()
if is_add_Bookmark.lower() != 'y':
print("\n仅完成书签部分格式化!\n")
print("\033[0;32;40m按Enter键退出!\033[0m\n")
input()
sys.exit()
pike_add_bookmark()
print("\n\033[0;32;40m"+filename+"\033[0m 加书签完成!\n\n")
print("\033[0;32;40m按Enter键退出!\033[0m\n")
input()


| 
 [复制链接]
[复制链接]

 发表于 2022-7-31 00:21
发表于 2022-7-31 00:21
 |
发表于 2022-8-1 21:09
|
发表于 2022-8-1 21:09





