Scrapy学习笔记
什么是Scrapy?
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
结构:
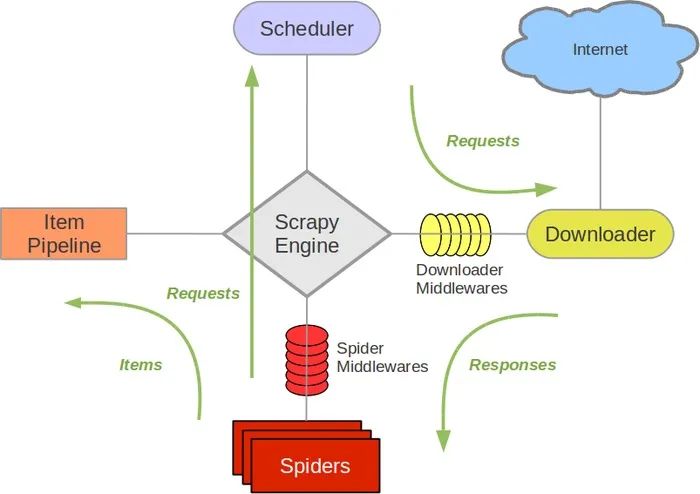
-
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
-
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
-
Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
-
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
-
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
-
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
总结:一个功能强大的爬虫框架:)接下来学习如何使用scrapy
安装
pip install Scrapy
一、创建项目
在终端输入:
scrapy startproject mySpider
生成的项目文件结构为:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
其中,
- scrapy.cfg为项目的配置文件。
- mySpider/为项目的Python模块,将会从这里引用代码。
- mySpider/items.py为项目的目标文件。
- mySpider/pipelines.py为项目的管道文件。
- mySpider/settings.py为项目的设置文件。
- mySpider/spiders/为存储爬虫代码目录。
二、创建蜘蛛
创建项目后,我们需要创建蜘蛛来爬取内容
蜘蛛的代码储存在mySpider/spiders/目录下
可以自行在文件夹中创建蜘蛛文件,也可以通过命令行自动完成创建
cd mySpider # 进入根目录
scrapy genspider biquge "xbiquwx.la" # biquge为蜘蛛名称,"xbiquwx.la"为目标url
创建完成后,在mySpider/spiders/目录下生成biquge.py文件,其内容为:
import scrapy
class BiqugeSpider(scrapy.Spider):
name = 'biquge' # 名称
allowed_domains = ['xbiquwx.la'] # 允许运行的域
start_urls = ['http://xbiquwx.la/'] # urls,该列表下的url将会依次进行请求
def parse(self, response): # 回调函数
pass
其中,parse()函数用于在每次迭代请求后处理响应
例1:对小说某章节进行内容提取,并写入txt
class BiqugeSpider(scrapy.Spider):
name = 'biquge'
allowed_domains = ['xbiquwx.la']
start_urls = ['https://www.xbiquwx.la/26_26516/10289395.html']
def parse(self, response): # 回调函数
content = response.xpath('//*[@id="content"]').extract_first() # 通过xpath提取内容
with open("result.txt", "w") as f:
f.write(content)
三、运行蜘蛛
在根目录下运行:
scrapy crawl biquge
运行例1中的蜘蛛,在根目录下得到result.txt
四、数据提取
1、控制台提取
使用shell来调试数据
scrapy shell "https://www.xbiquwx.la/26_26516/10289395.html"
shell将请求该页面的代码,并开始调试
通过response.css()的方法来定位元素,并返回一个或多个选择器
例2:一些定位样式:
>>> response.css("div.bottom") # 选择div标签下class="bottom"的元素
>>> response.css(".bottom") # 选择所有class="bottom"的元素
>>> response.css("#content") # 选择所有id="bottom"的元素
scrapy将返回一个列表用于储存选择器
>>> title = response.css("title")[0]
>>> title_content = title.css("title::text").get() # '::'符号用于提取该元素下的特定属性,如'text''href'等
>>> title_content = title.css("::text").get() # 对于本元素下的属性,可以省略本元素标签
>>> title_content = title.css("br,::text").getall() # 选取多个元素,用','隔开,使用getall()方法提取
更简略的是,对于简单的元素,可以将上面的步骤合并起来:
>>> title = response.css("title::text").get()
>>> content = response.css("div#content").get()
2、代码提取
将上面的提取过程放在回调函数中:
import scrapy
class BiqugeSpider(scrapy.Spider):
name = 'biquge' # 名称
allowed_domains = ['xbiquwx.la'] # 允许运行的域
start_urls = ['https://www.xbiquwx.la/26_26516/10289395.html'] # urls,该列表下的url将会依次进行请求
def parse(self, response): # 回调函数
for box in response.css('div.box_con'):
yield {
'content': box.css('div#content::text').getall(),
}
运行蜘蛛并将结果保存至json文件中:
scrapy crawl biquge -O result.json # 可以使用json、xml、csv、jl(json line)
五、管道处理
管道用于蜘蛛提取数据后,进行的数据处理和下载任务
管道定义在piplines.py文件中
from itemadapter import ItemAdapter
class MyspiderPipeline:
def __init__(self): # 管道初始化时的方法
pass
def process_item(self, item, spider): # 管道处理数据的方法(necessary),输入参数为item
return item # 处理完毕后返回引擎 (necessary)
def open_spider(self, spider): # 蜘蛛开启时的方法
pass
def close_spider(self, spider): # 管道关闭时的方法
pass
附录 CSS选择器
| 选择器 |
示例 |
示例说明 |
| class |
.intro |
选择所有class="intro"的元素 |
| #id |
#firstname |
选择所有id="firstname"的元素 |
| * |
* |
选择所有元素 |
| element |
p |
选择所有<p>元素 |
| element,element |
div,p |
选择所有<div>元素和<p>元素 |
| element element |
div p |
选择<div>元素内的所有<p>元素 |
| element>element |
div>p |
选择所有父级是 <div> 元素的 <p> 元素 |
| element+element |
div+p |
选择所有紧接着<div>元素之后的<p>元素 |
| [attribute] |
[target] |
选择所有带有target属性元素 |
| [attribute=value] |
[target=-blank] |
选择所有使用target="-blank"的元素 |
| [attribute~=value] |
[title~=flower] |
选择标题属性包含单词"flower"的所有元素 |
| [attribute|=language] |
[lang|=en] |
选择一个lang属性的起始值="EN"的所有元素 |
| :link |
a:link |
选择所有未访问链接 |
| :visited |
a:visited |
选择所有访问过的链接 |
| :active |
a:active |
选择活动链接 |
| :hover |
a:hover |
选择鼠标在链接上面时 |
| :focus |
input:focus |
选择具有焦点的输入元素 |
| :first-letter |
p:first-letter |
选择每一个<P>元素的第一个字母 |
| :first-line |
p:first-line |
选择每一个<P>元素的第一行 |
| :first-child |
p:first-child |
指定只有当<p>元素是其父级的第一个子级的样式。 |
| :before |
p:before |
在每个<p>元素之前插入内容 |
| :after |
p:after |
在每个<p>元素之后插入内容 |
| :lang(language) |
p:lang(it) |
选择一个lang属性的起始值="it"的所有<p>元素 |
| element1~element2 |
p~ul |
选择p元素之后的每一个ul元素 |
| [attribute^=value] |
a[src^="https"] |
选择每一个src属性的值以"https"开头的元素 |
| [attribute$=value] |
a[src$=".pdf"] |
选择每一个src属性的值以".pdf"结尾的元素 |
| [attribute*=value] |
a[src*="runoob"] |
选择每一个src属性的值包含子字符串"runoob"的元素 |
| :first-of-type |
p:first-of-type |
选择每个p元素是其父级的第一个p元素 |
| :last-of-type |
p:last-of-type |
选择每个p元素是其父级的最后一个p元素 |
| :only-of-type |
p:only-of-type |
选择每个p元素是其父级的唯一p元素 |
| :only-child |
p:only-child |
选择每个p元素是其父级的唯一子元素 |
| :nth-child(n) |
p:nth-child(2) |
选择每个p元素是其父级的第二个子元素 |
| :nth-last-child(n) |
p:nth-last-child(2) |
选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 |
| :nth-of-type(n) |
p:nth-of-type(2) |
选择每个p元素是其父级的第二个p元素 |
| :nth-last-of-type(n) |
p:nth-last-of-type(2) |
选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 |
| :last-child |
p:last-child |
选择每个p元素是其父级的最后一个子级。 |
| :root |
:root |
选择文档的根元素 |
| :empty |
p:empty |
选择每个没有任何子级的p元素(包括文本节点) |
| :target |
#news:target |
选择当前活动的#news元素(包含该锚名称的点击的URL) |
| :enabled |
input:enabled |
选择每一个已启用的输入元素 |
| :disabled |
input:disabled |
选择每一个禁用的输入元素 |
| :checked |
input:checked |
选择每个选中的输入元素 |
| :not(selector) |
:not(p) |
选择每个并非p元素的元素 |
| ::selection |
::selection |
匹配元素中被用户选中或处于高亮状态的部分 |
| :out-of-range |
:out-of-range |
匹配值在指定区间之外的input元素 |
| :in-range |
:in-range |
匹配值在指定区间之内的input元素 |
| :read-write |
:read-write |
用于匹配可读及可写的元素 |
| :read-only |
:read-only |
用于匹配设置 "readonly"(只读) 属性的元素 |
| :optional |
:optional |
用于匹配可选的输入元素 |
| :required |
:required |
用于匹配设置了 "required" 属性的元素 |
| :valid |
:valid |
用于匹配输入值为合法的元素 |
| :invalid |
:invalid |
用于匹配输入值为非法的元素 |

 [复制链接]
[复制链接]
 发表于 2022-6-23 19:58
发表于 2022-6-23 19:58
 |
发表于 2022-6-23 20:31
|
发表于 2022-6-23 20:31





