本帖最后由 d8349565 于 2022-4-8 20:53 编辑
xcl615 发表于 2022-4-8 18:47
楼主体验了一下,可以分享一下源码嘛,我可以优化一下
代码是中午午休写的,没怎么优化,比较乱
[Python] 纯文本查看 复制代码 import os
from aip import AipOcr
import re
from pandas import DataFrame
from easygui import diropenbox
from tqdm import tqdm
print('程序开始运行,进度如下:')
""" 你的 APPID AK SK """
APP_ID = '23539899' # 申请应用获取的 ID,下同
API_KEY = '自行获取'
SECRET_KEY = '自行获取'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
path=diropenbox('请选择需要处理的文件夹')
filelist = os.listdir(path) # 设定图片目录
result = []
for file in tqdm(filelist):
a = {}
file_path=f'{path}\\{os.path.basename(file)}'
img = get_file_content('{}\\'.format(path) + file)
message = client.basicGeneral(img)['words_result']
x = [str(list(i.values())[0]) for i in message]
x_str = ','.join(x).replace('(请尽快接种新冠疫苗)','')
# 获取最新的检测时间
核酸检测时间 = re.compile(r',((.){12})检测,').findall(x_str)
num = len(核酸检测时间) - 1
核酸检测时间 = 核酸检测时间[num][0]
# 获取截屏时间
time = re.compile(r',(2022-(.){5})').findall(x_str)
num = len(time) - 1
time = time[num][0]
# 获取姓名
name = re.compile(r',([\u4e00-\u9fa5]{2,4}),')
name = name.findall(x_str)
try:
name.remove('场所码')
except:
pass
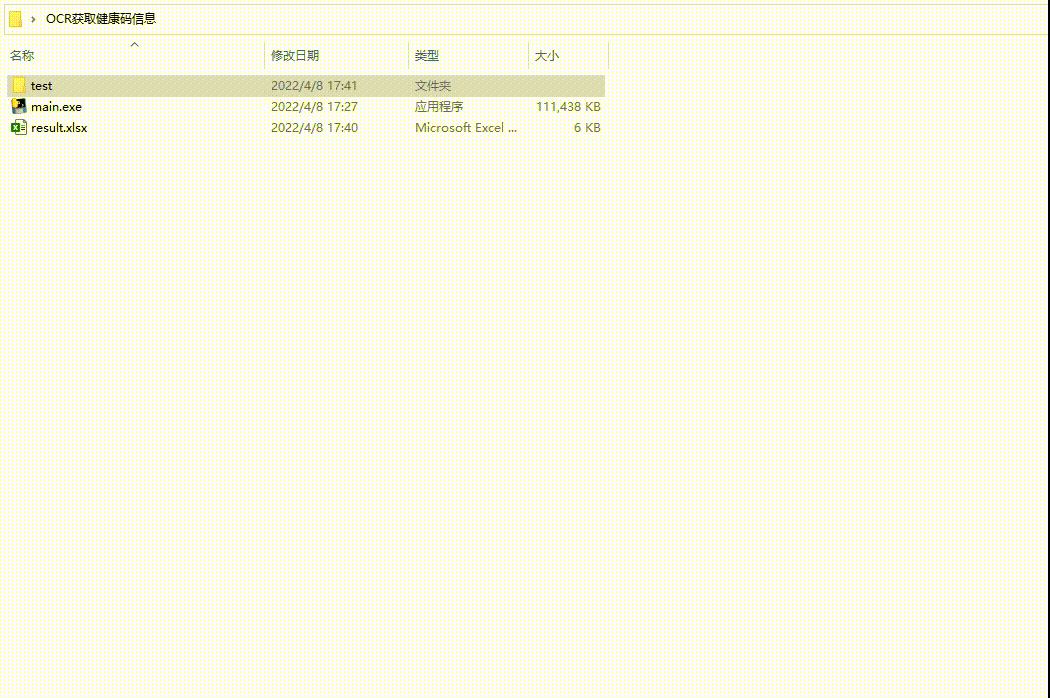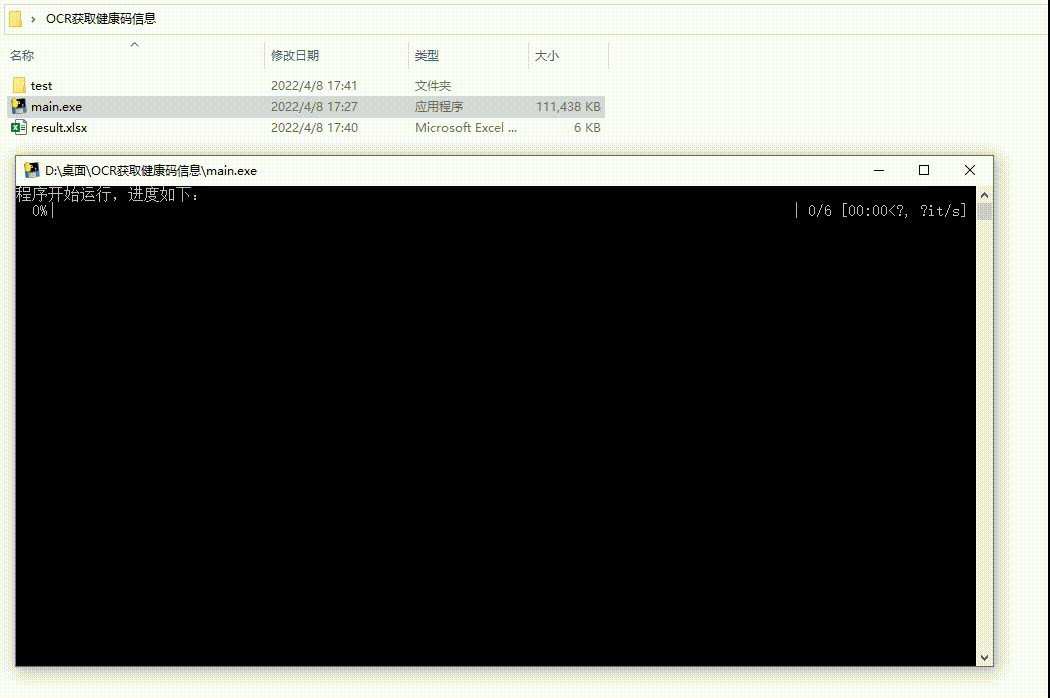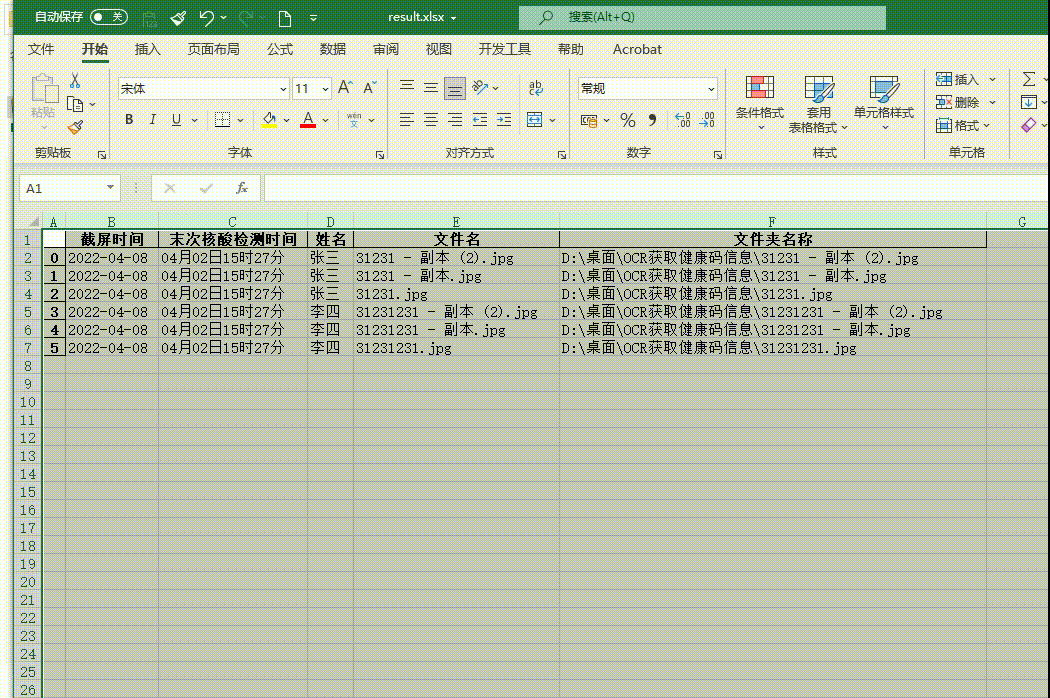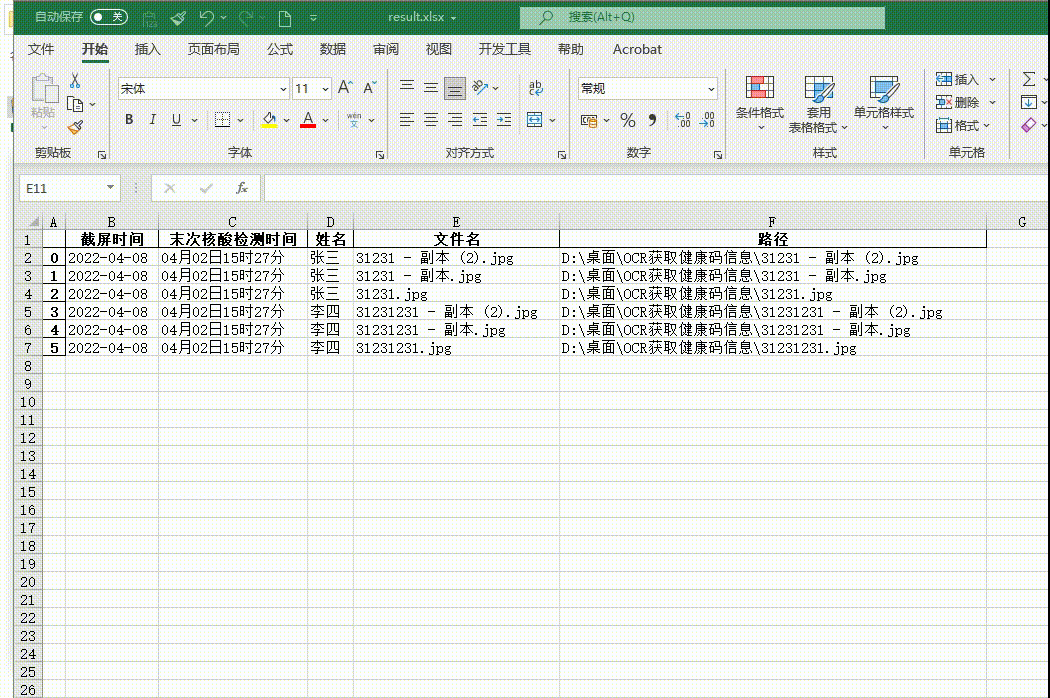
a['截屏时间'] = time
a['末次核酸检测时间'] = 核酸检测时间
a['姓名'] = name[0]
a['文件名'] = file
a['文件夹名称'] = os.path.abspath(file)
# print(' 截屏时间为:', time, ' 末次核酸检测时间为:', 核酸检测时间, '姓名为:', name[0],file)
result.append(a)
print(result)
result=DataFrame(result).to_excel('result.xlsx')
os.startfile('result.xlsx')
input('程序运行完成') | 

 [复制链接]
[复制链接]

 发表于 2022-4-8 18:08
发表于 2022-4-8 18:08
 |
发表于 2022-4-8 20:51
|
发表于 2022-4-8 20:51




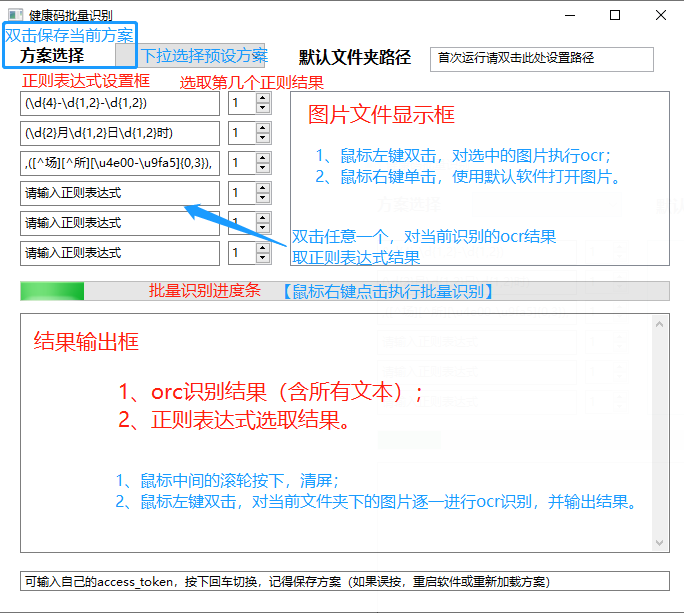
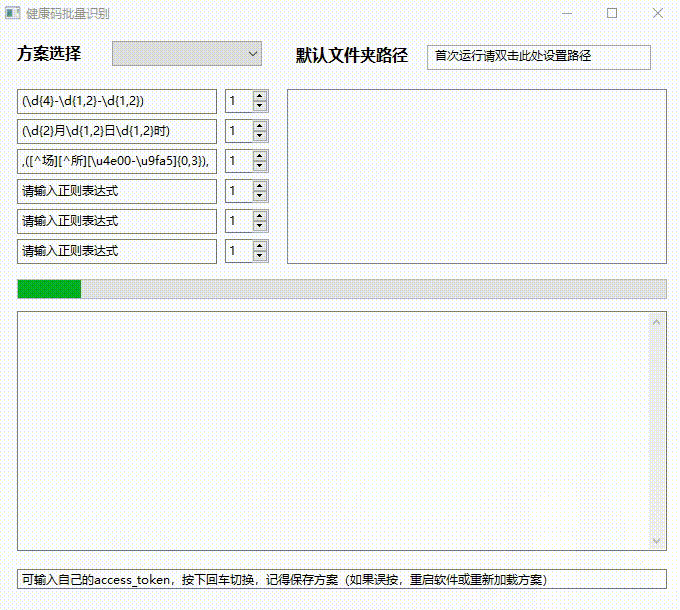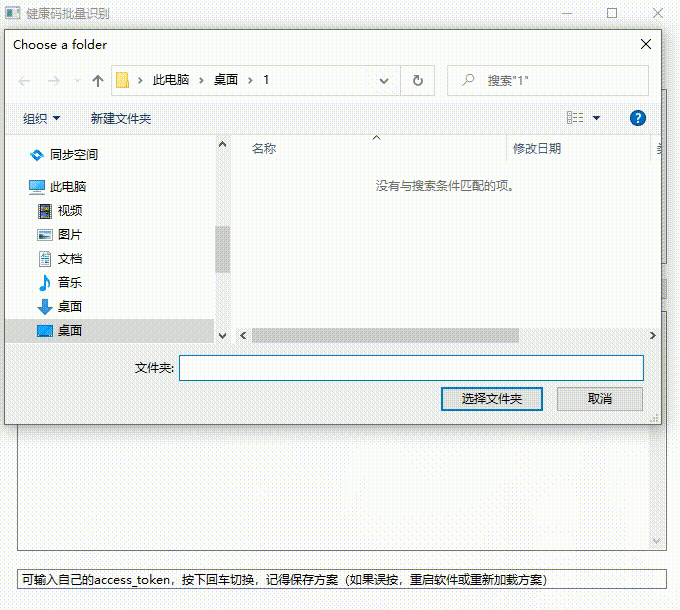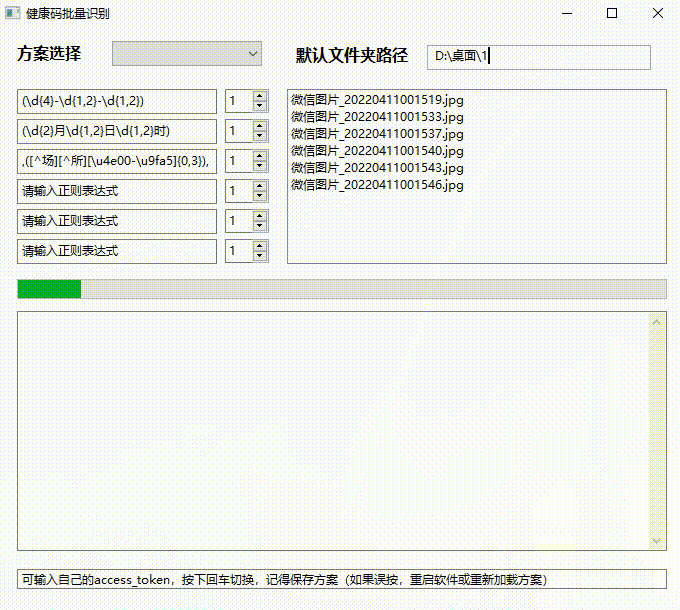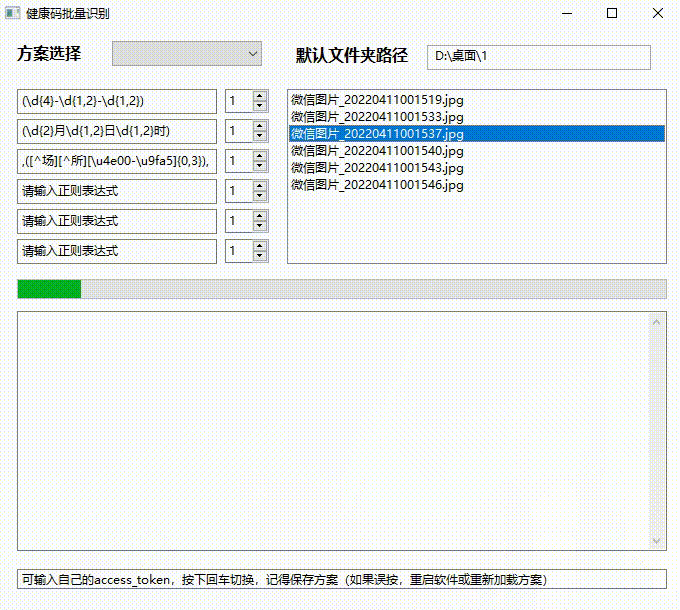
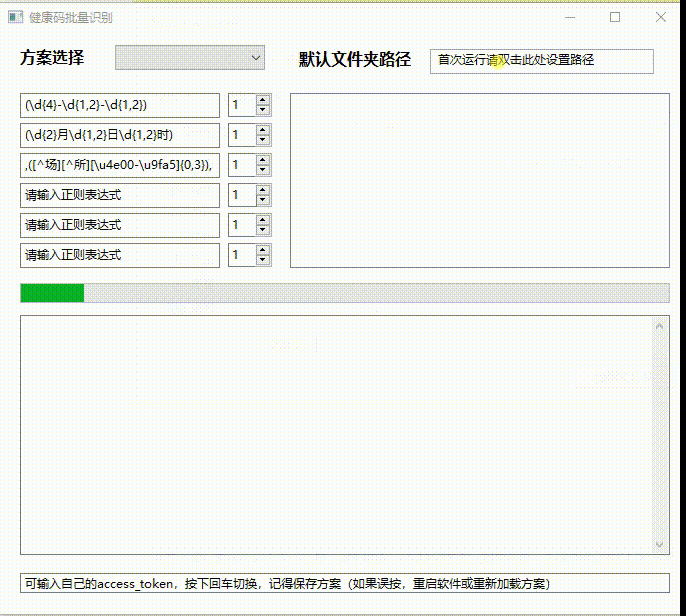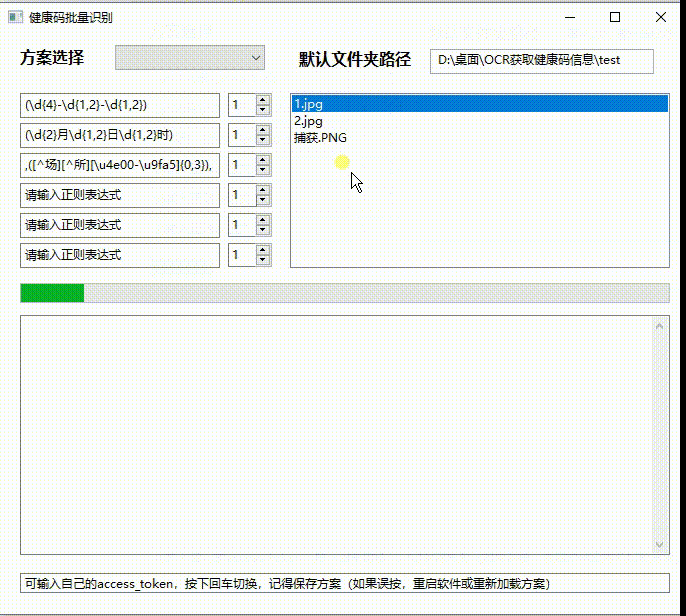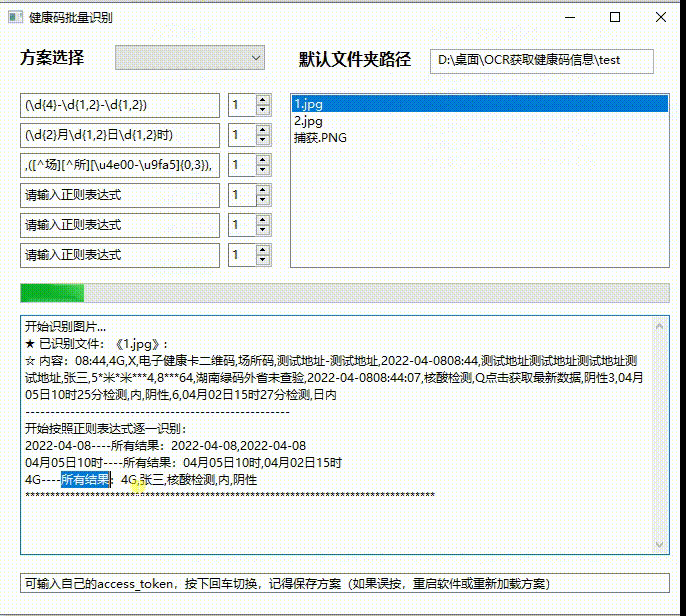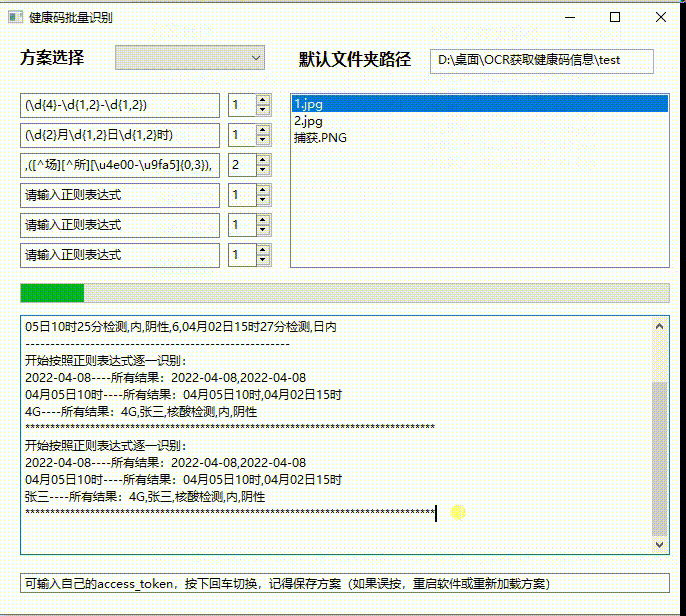
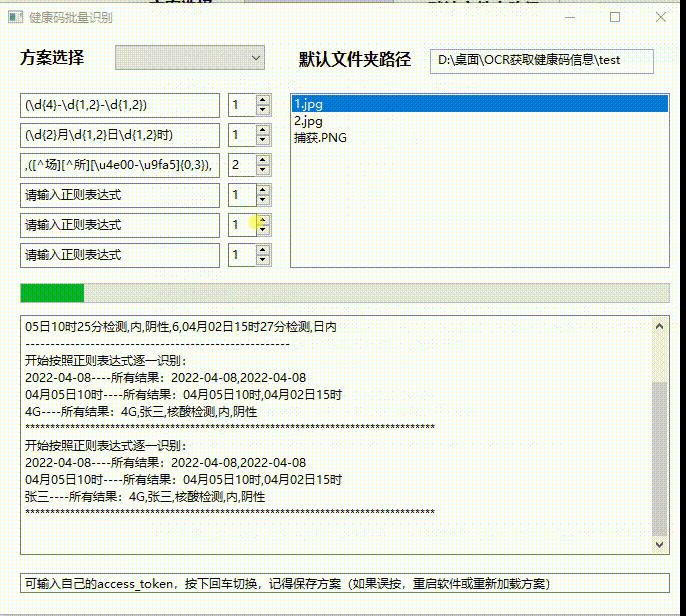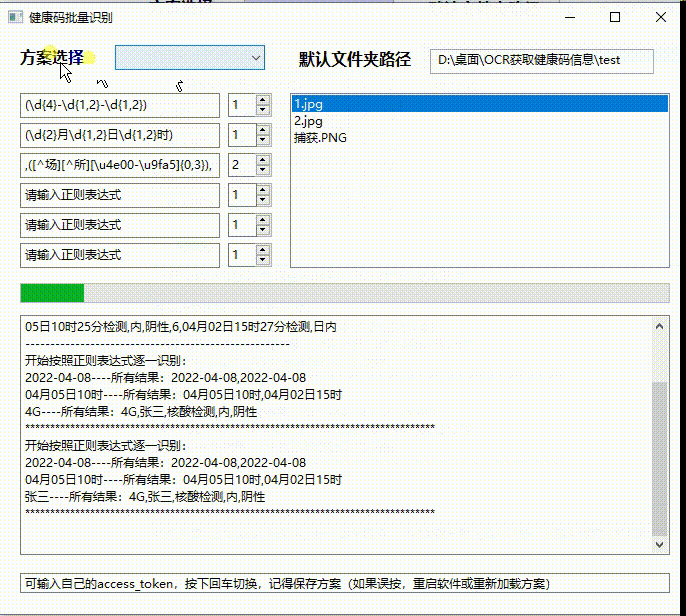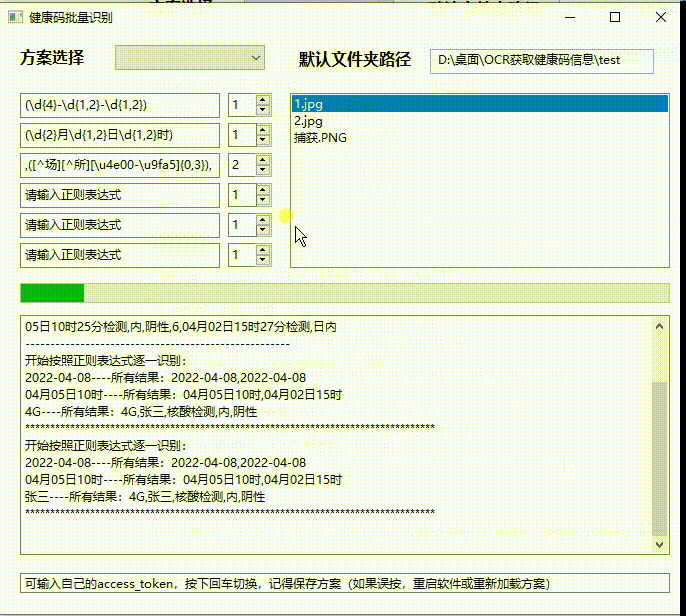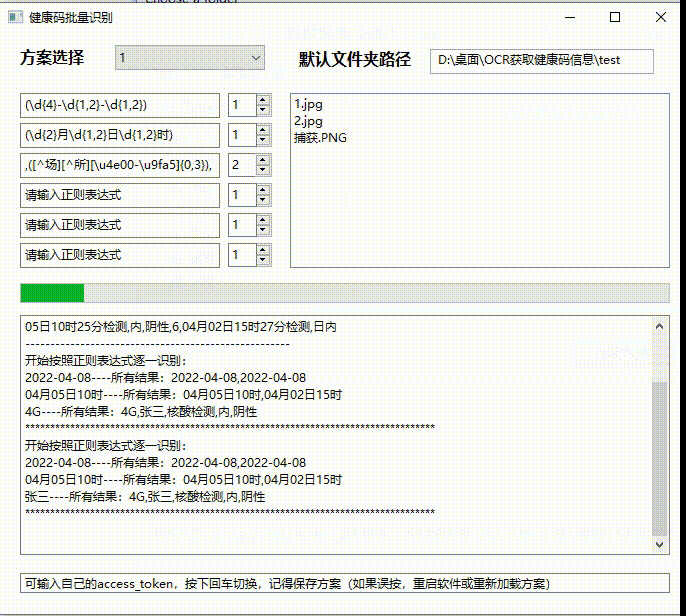
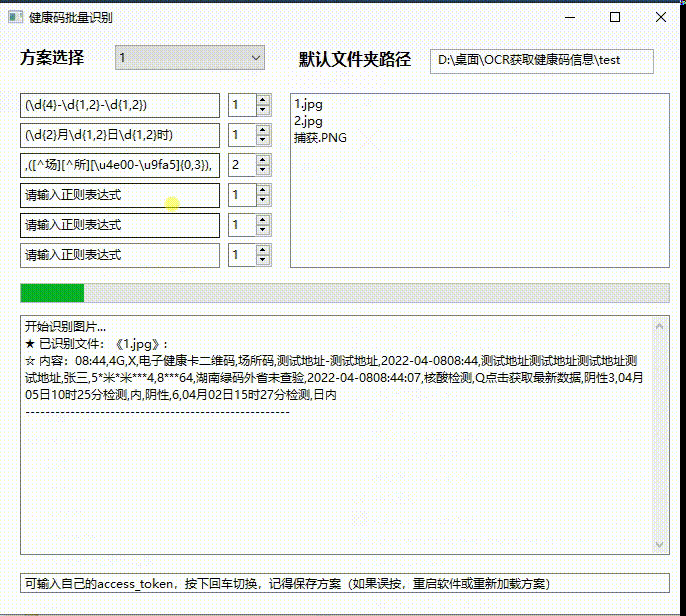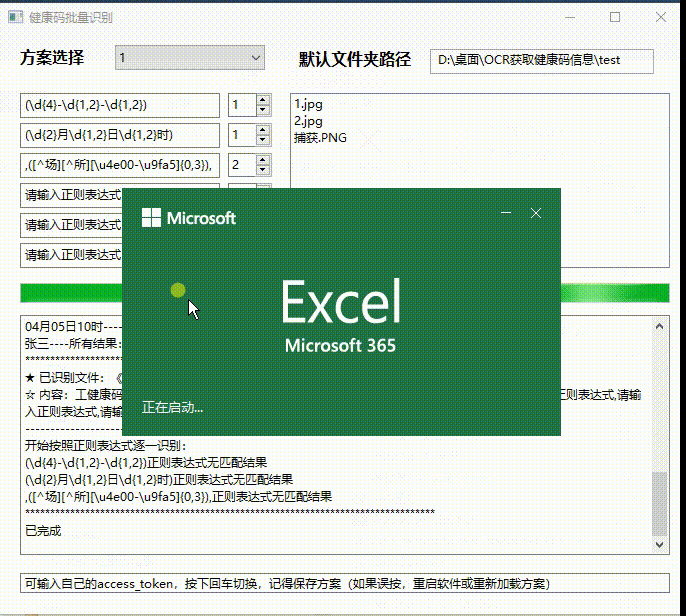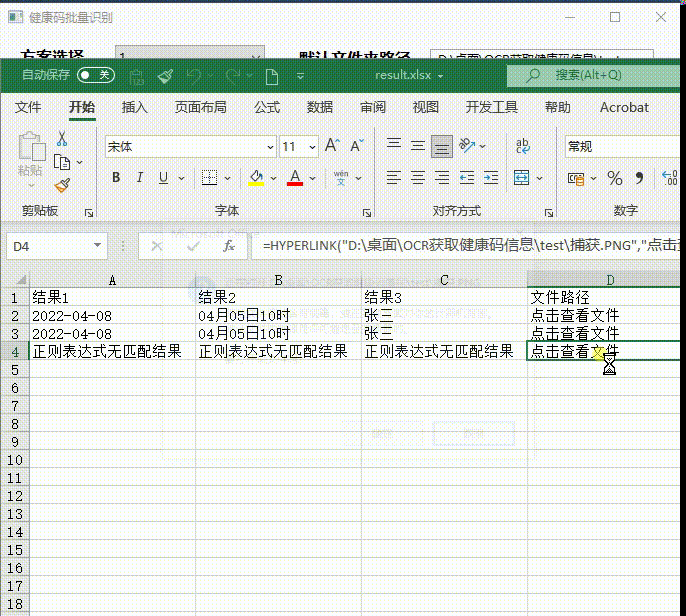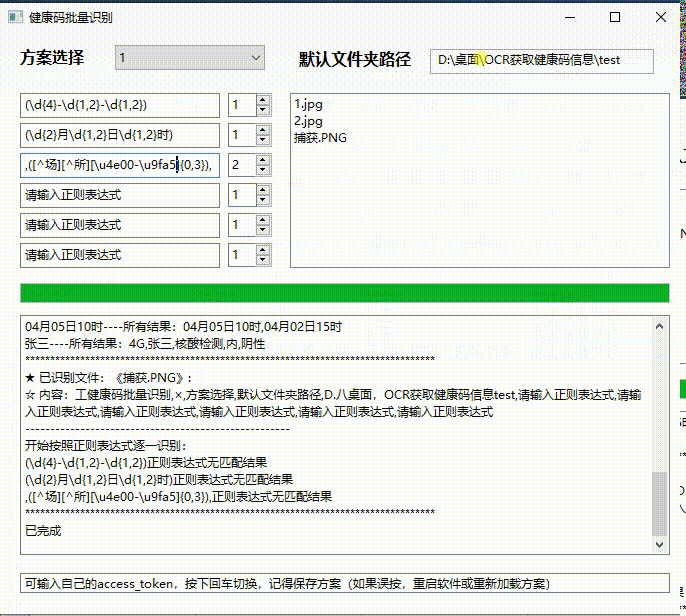
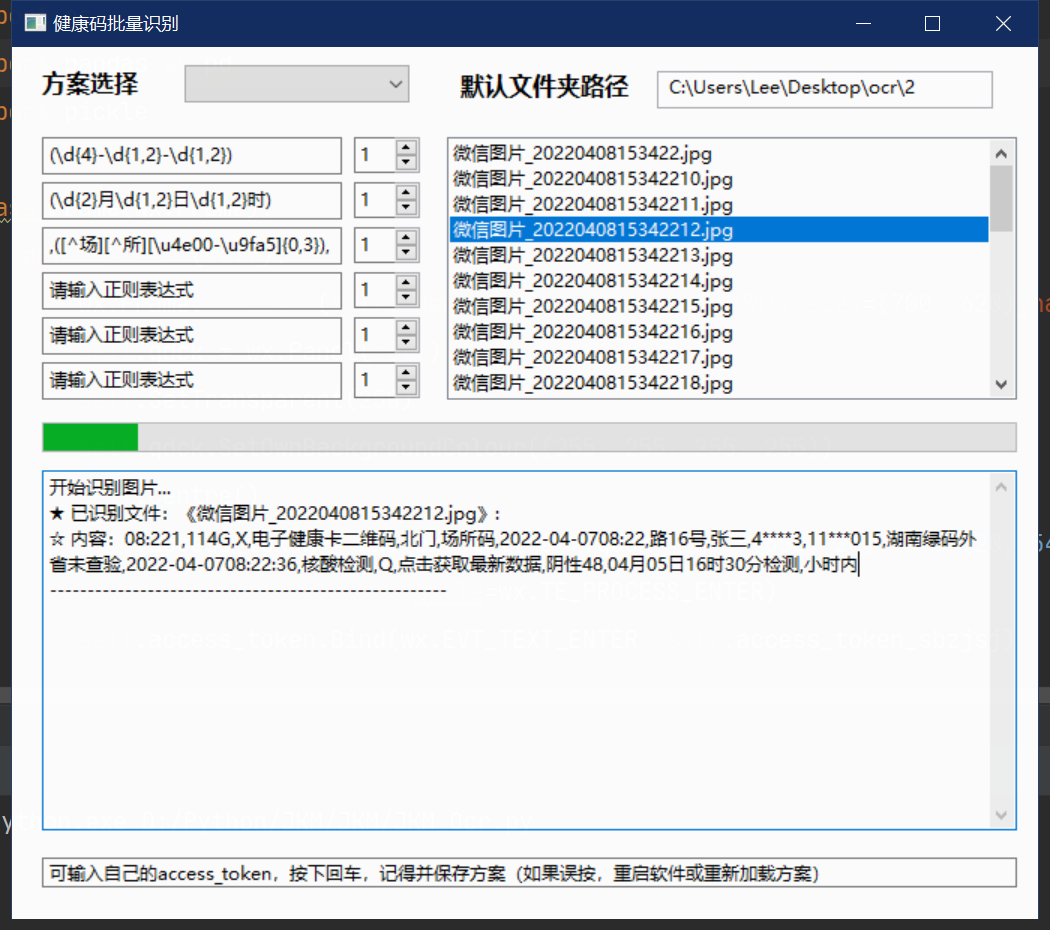

 真的牛 不符不行
真的牛 不符不行
