Python美女图片爬虫实战
准备工作
-
python3开发环境
-
相应的python包:
import urllib.request
from lxml import etree
import re
import os
import datetime
-
开发环境:为了方便测试,
我这里使用的是Jupyter notebook进行开发测试。
当然也可以使用其他的开发环境,例如PyCharm。
-
谷歌浏览器 :用于抓包分析(其他浏览器也可以,例如火狐浏览器)
(更详细的关于安装python包的安装这里就不说了,毕竟这个不是入门教程)
分析网页结构
网站:https://www.mn52.com/ mn52图库网(是正规的网站,没有露点,不属于色情范围,是合法的)
这个网站是一个图片网站,内容基本都是图片,分类有很多,因为网页结构都是一样的,所以我这里选取了性感美女这个分类进行分析。
性感美女:https://www.mn52.com/xingganmeinv/
因为我要爬取这个分类下的所有图片,所以首先我要分析这个url的组成。
爬取的时候是1~220页,每一页有20组图片(即一页有20个缩略图,点击进去才是我们需要获取的原图)。
分析完成之后思路如下:获取每一页的url → 获取每一页的20个详情页面的url → 获取每一详情页下的原图url → 下载每组图片的原图到本地。最后使用循环进行爬取。
大致的思路就是这样,下面开始写代码进行测试。
写代码分析
列表的url组成
第一页
https://www.mn52.com/xingganmeinv/list_1_1.html
第二页
https://www.mn52.com/xingganmeinv/list_1_2.html
末页
https://www.mn52.com/xingganmeinv/list_1_220.html
url组成:
url="https://www.mn52.com/xingganmeinv/list_1_" + number +".html" (number=1-->200)
详情页url的获取
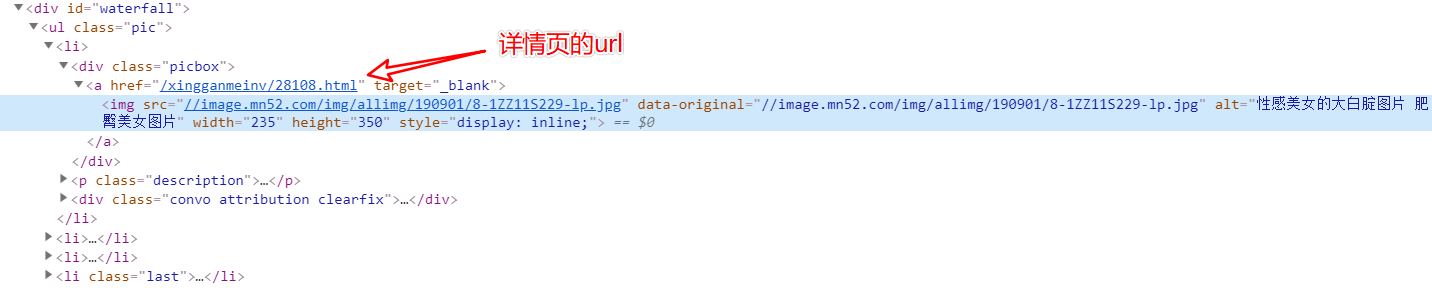
然后根据 Xpath表达式进行获取
//div[@id="waterfall"]/ul/li/div/a/@href
详情页下的所有图片url

使用 Xpath表达式获取
//div/ul[@id="pictureurls"]/li/div/a/img/@src
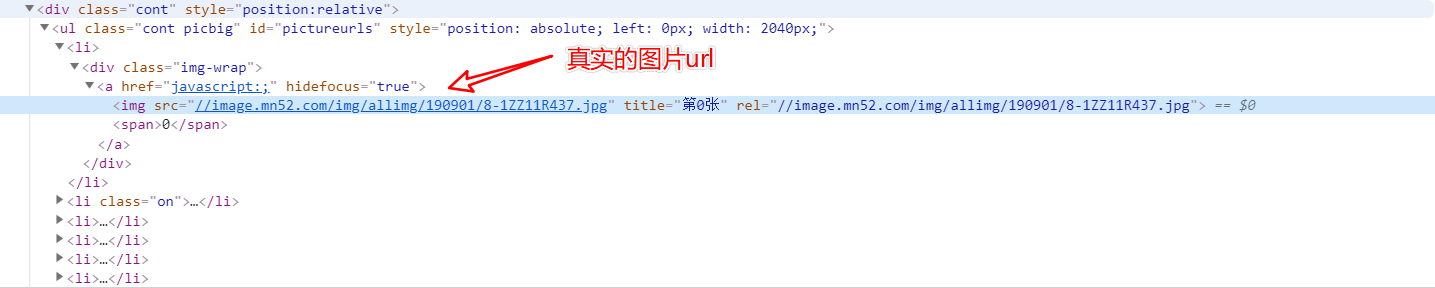
图片命名规则
图片的类型
由于每一组图片都是一样的格式保存的,要么是 .jpg,要么是 .png,所以我这里只是知道一张图片的保存格式即可,即获取到第一张图片的url后缀即可。
例如:实际的详情页下的某张图片的url组成
https://image.mn52.com/img/allimg/190827/8-1ZRH10243.png
https://image.mn52.com/img/allimg/190818/8-1ZQR13348.jpg
这里我们需要获取的是后面的四个字符
由于前面已经获取了每一个详情页下的所有原图url的列表[ ],这里只需要获取列表的第一个元素的后四个字符即可。
# src列表下的第一个元素 (src是所有的原图url列表)
firstSrc = src[0]
# 获取字符串的最后四个字符
filetype = firstSrc[-4:]
图片的命名
由于我们需要下载的图片很多,可能有几万张,甚至超过几十万张,所有一个好的命名方式显得很重要。
这里我按照图片原来的命名去命名,即是我需要获取到图片原来的命名名称。
在分析测试过程中,我发现图片命名可能存在以下两种(可能不止两种)
https://image.mn52.com/img/allimg/190827/8-1ZRH10243.png
https://image.mn52.com/img/allimg/c160322/145V4939360050-3110O.jpg
我这里需要获取的是
8-1ZRH10243
145V4939360050-3110O
由于图片类型前面已经获取到了,这里不需要再次获取。(或者也可以直接在这里获取名称和类型,直接省略上一步获取图片类型)
这里我使用正则表达式进行获取
# src是原图的url
pattern = '\w*?\-\w+'
name = re.search(pattern,src).group()
print(name)
# src = 'https://image.mn52.com/img/allimg/c150926/144323X0404I0-1261301.jpg'
# 结果144323X0404I0-1261301
# src = 'https://image.mn52.com/img/allimg/190818/8-1ZQR14016.jpg'
# 结果8-1ZQR14016
这样我们就可以获取到图片的名称了,无论怎么变化,这个正则表达式应该都可以满足这里的需求了。
反爬的解决
前面的工作完成之后,我迫不及待的进行了测试。
然而却遇到了403,404错误…
经过分析,我认为网站设置了防盗链
解决方案:
- 模拟浏览器爬取
- 设置header为该网站链接发出的跳转请求
最后成功解决了。
然后下载了几个小时,下载了21330张性感美女图片,这里只是爬取了1~120页的图片,后面的没有继续去爬取。
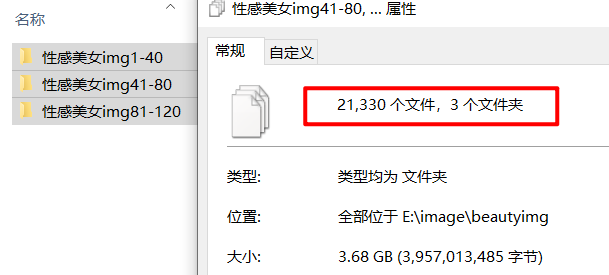
自动爬取效果
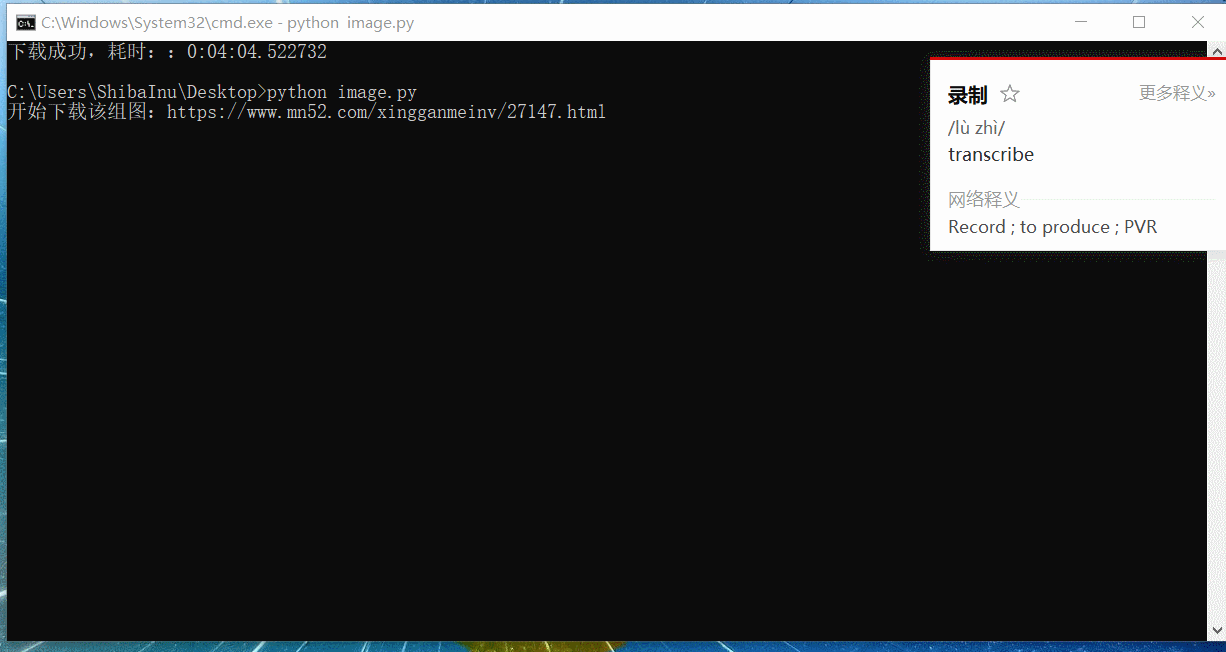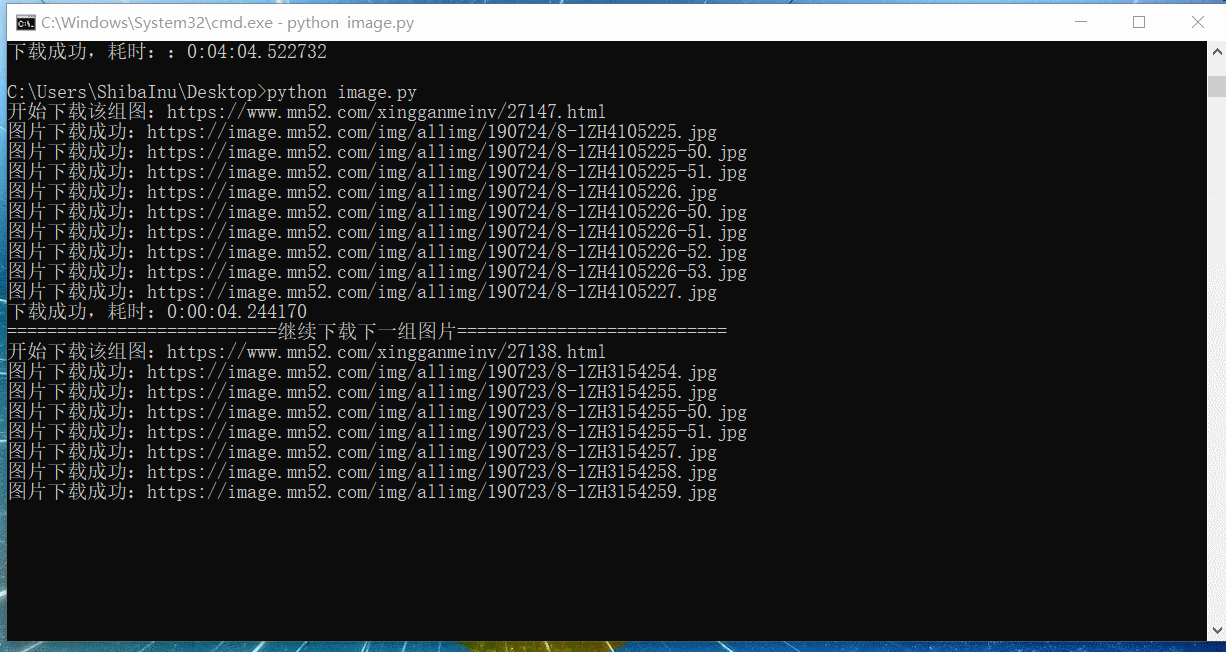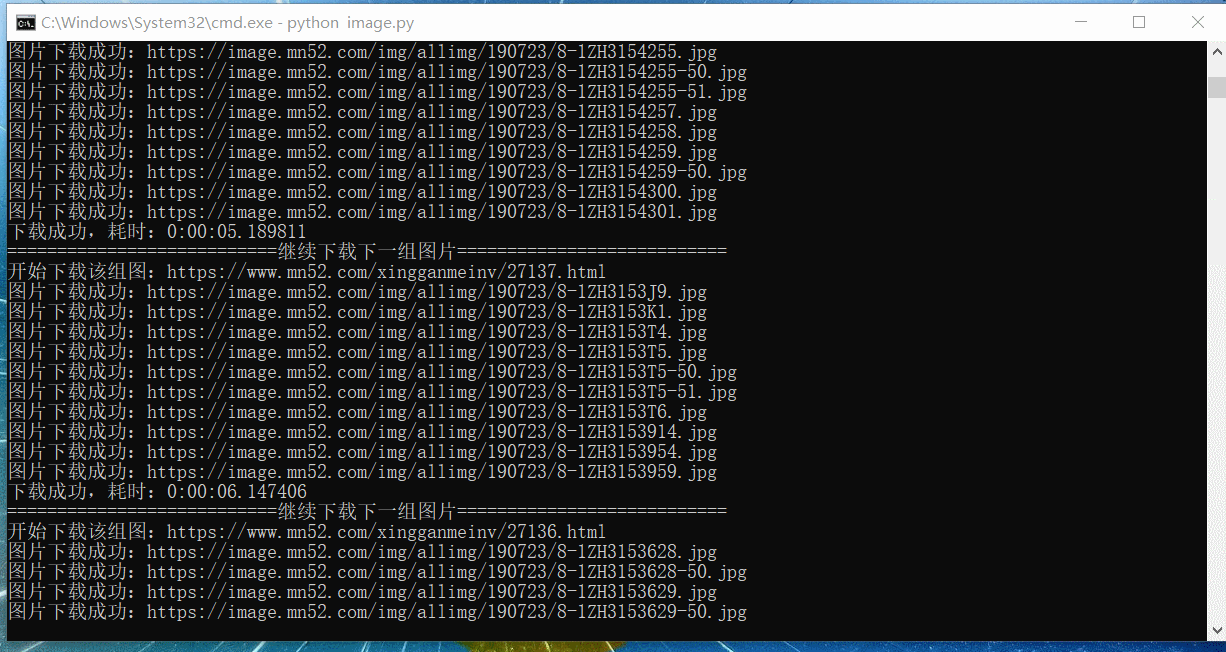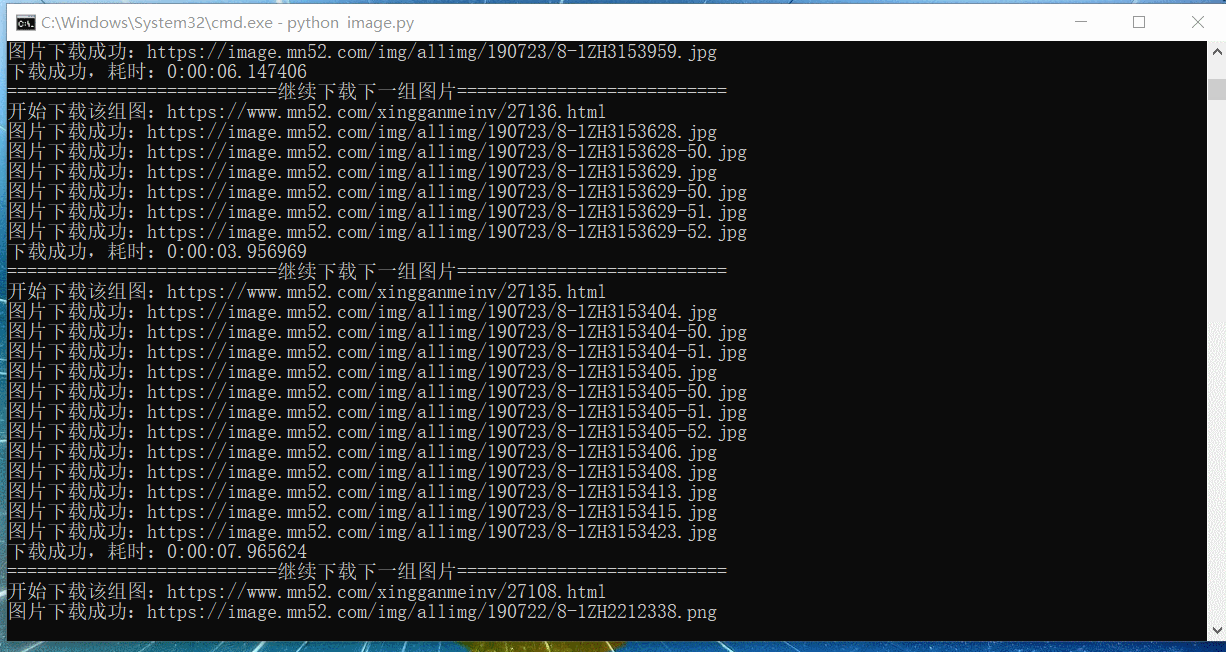
程序可以改进之处
完整代码
代码写的不是很好,大家将就看吧(现在主要做Java后端,python写的很少了)。
import urllib.request
from lxml import etree
import re
import os
import datetime
# 下载图片(获取原图链接并下载)
def downloadImage(url,pathway):
response = urllib.request.urlopen(url)
content=response.read().decode(encoding='utf-8')
dom = etree.HTML(content)
src=dom.xpath('//div/ul[@id="pictureurls"]/li/div/a/img/@src')
# 获取图片链接和名称并下载图片
pattern = '\w+\-\w+'
firstsrc = src[0]
filetype = firstsrc[-4:]
headers = [('Host','www.mn52.com'), ('Connection', 'keep-alive'), ('Cache-Control', 'max-age=0'),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3'),
('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'),
('Accept-Encoding','gzip, deflate, br'),
('Accept-Language', 'zh-CN,zh;q=0.9'),
('If-None-Match', '5d652a1c-3d43'),
('Referer','https://www.mn52.com/xingganmeinv/'),
('If-Modified-Since', 'Tue, 27 Aug 2019 10:09:54 GMT')]
opener = urllib.request.build_opener()
opener.addheaders = headers
for img in src:
name = re.search(pattern,img).group()
if str(img[1:4])=="img":
imgUrl = "https://image.mn52.com" + img
else:
imgUrl = "https:" + img
data = opener.open(imgUrl)
# 储存路径
path = pathway + "/" + str(name) + str(filetype)
f = open(path,"wb")
f.write(data.read())
f.close()
print("图片下载成功:"+imgUrl)
# 构造分类的 url
# typeNum 性感美女-->1 清纯美女-->2 韩国美女-->3 欧美图片-->4 美女明星-->5
def getUrl(typeNum):
type = ""
if typeNum==1:
type = "xingganmeinv"
elif typeNum==2:
type = "meihuoxiezhen"
elif typeNum==3:
type = "rihanmeinv"
elif typeNum==4:
type = "jingyannenmo"
elif typeNum==5:
type = "meinvmingxing"
url1 = "https://www.mn52.com/"
url2 = "/list_"
url = url1 + type + url2 + str(typeNum) + "_"
return url;
# 提示信息
print("################################################################################")
print("# #")
print("# (1)作者:ShibaInu mn52图库:https://www.mn52.com #")
print("# #")
print("# (2)==> 需要输入:文件储存路径,例如 D:/image #")
print("# 下载的图片都会保存在这个文件夹 #")
print("# #")
print("# (3)==> 需要输入:图片类别 Number #")
print("# 性感美女 ==>[ 1 ] #")
print("# 清纯美女 ==>[ 2 ] #")
print("# 韩国美女 ==>[ 3 ] #")
print("# 欧美图片 ==>[ 4 ] #")
print("# 美女明星 ==>[ 5 ] #")
print("# #")
print("# (4)==> 需要输入:下载的起始页和末尾页的页码数 #")
print("# 起始页[ startPage ] #")
print("# 末尾页[ endPage(不包含末尾页)] #")
print("# #")
print("################################################################################")
print("")
pathway = input(" ①请输入文件存储路径(例如 D:/image):")
print("")
typeNum = input(" ②请输入下载的类别:")
urlList = getUrl(int(typeNum))
print("")
startPage = input(" ③请输入起始页 startPage:");
print("")
endPage = input(" ④请输入末尾页 endPage:")
print("")
print(" == 即将开始精彩资源的下载 == ")
print("")
startNum = int(startPage)
endNum = int(endPage)
startTime = datetime.datetime.now()
for n in range(startNum,endNum):
realurl = urlList + str(n) + '.html'
response = urllib.request.urlopen(realurl)
content=response.read().decode(encoding='utf-8')
dom = etree.HTML(content)
src=dom.xpath('//div[@id="waterfall"]/ul/li/div/a/@href')
for img in src:
path = 'https://www.mn52.com'+ img
indexImg = src.index(img)
#异常处理:遇到异常信息跳过
try:
print("开始下载该组图:" + path)
starttime = datetime.datetime.now()
downloadImage(path,pathway)
endtime = datetime.datetime.now()
print (" 下载成功,耗时:" + str(endtime - starttime))
print (" =========> 第"+ str(indexImg+1) +"组图片下载完成 <=========")
print("")
except Exception as e:
print(" =========> 第"+ str(indexImg+1) +"组图片下载完成 <=========")
pass
continue
print("===========================> 第"+ str(n) +"个图片列表下载完成 <===========================")
endTime = datetime.datetime.now()
print ("下载成功,耗时::" + str(endTime - startTime))
打包成 .exe可以执行文件
下载一张 mn52.ico 图片,将mn52pic.py 和这张图片放在同一个文件夹下,cmd 命令行进入这个目录,然后执行下面的代码打包:
pyinstaller -F -i mn52.ico mn52pic.py
后记
由于这个图片网站服务器性能不是非常好,所以大家也不要一直进行爬取和测试,以上只是为了讲解一下图片爬虫的简单实现。



 [复制链接]
[复制链接]
 |
发表于 2019-11-11 23:39
|楼主
|
发表于 2019-11-11 23:39
|楼主 发表于 2020-5-17 22:15
发表于 2020-5-17 22:15





 收藏
收藏 淘帖
淘帖 有用
有用 分享到朋友圈
分享到朋友圈
