准备工作
分析请求头信息
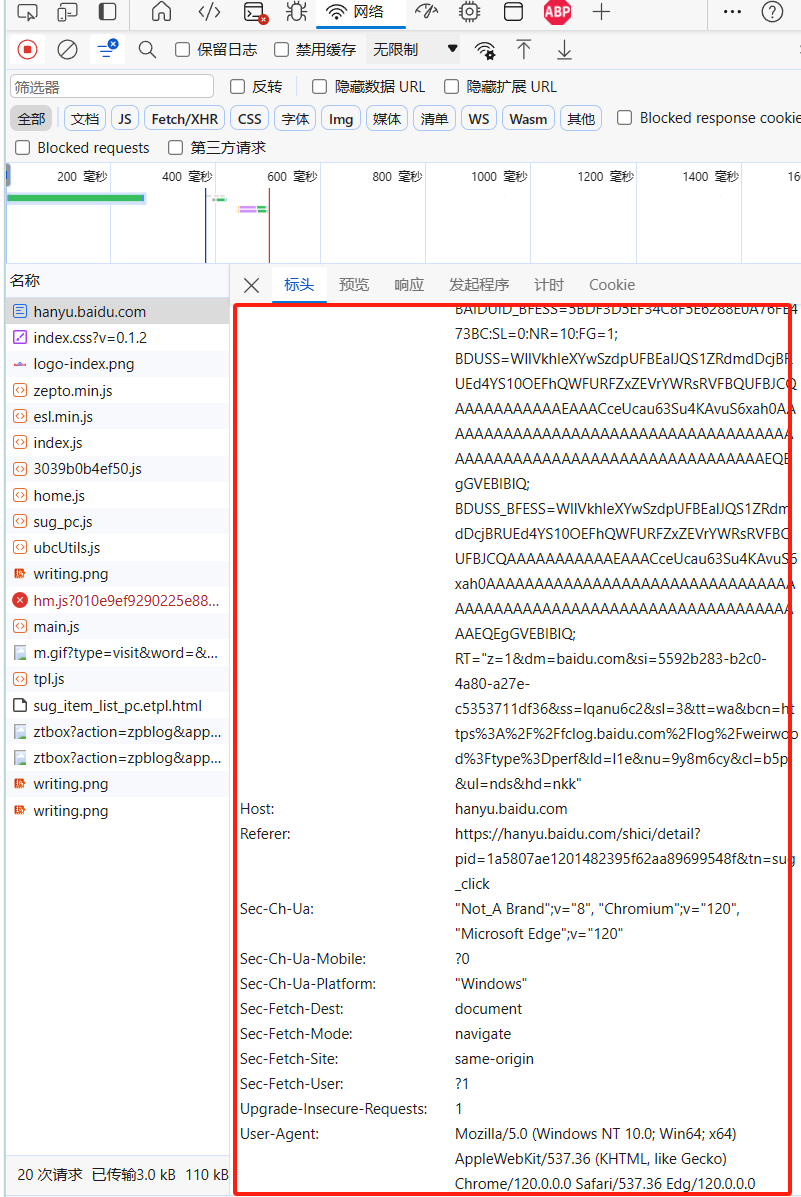
- 为了防止限制,打开百度汉语官网并登录,使用浏览器F12复制所有请求头信息,其中cookie是登录信息
分析根据关键字查找所有词语的列表接口
-
在百度汉语主页面搜索关键字“诗词大全”,会以列表的形式展现所有相关的词语,

-
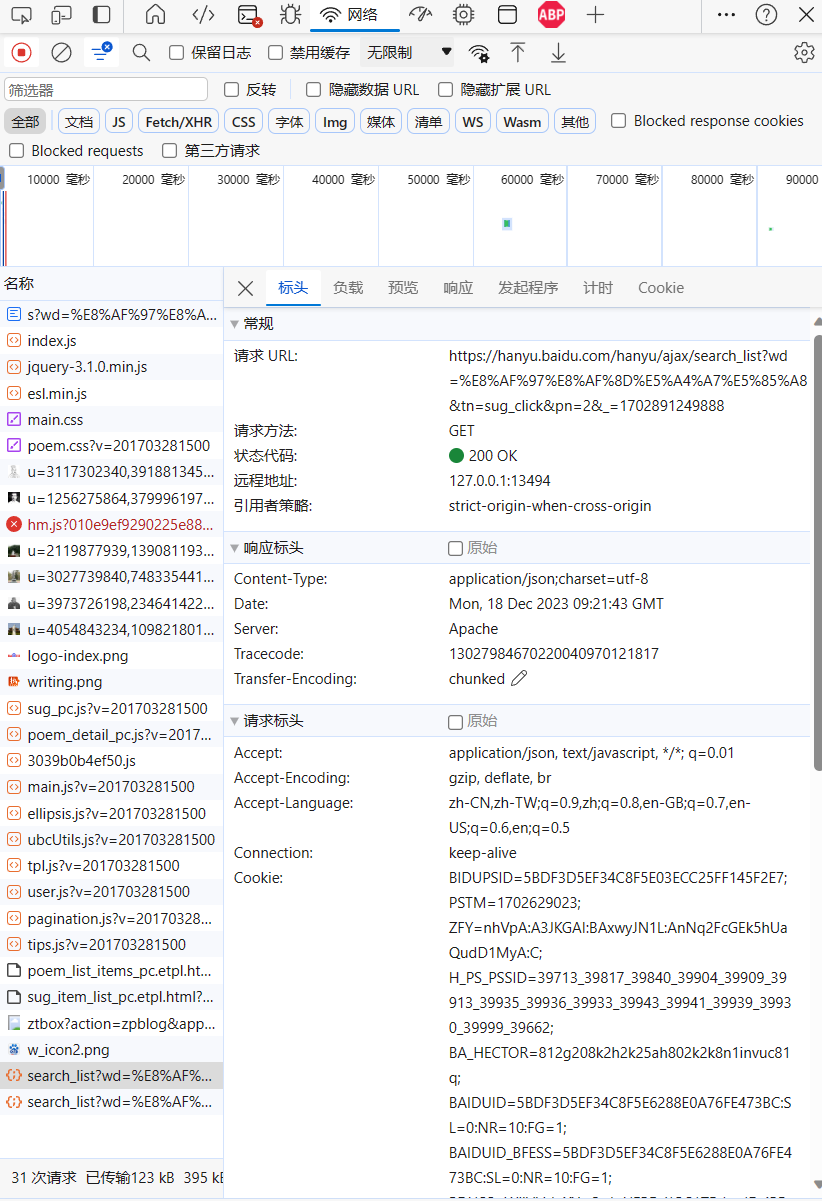
使用F12或者是其他的抓包工具,分析到新接口会返回对应的词典信息,如下:
-
分析参数
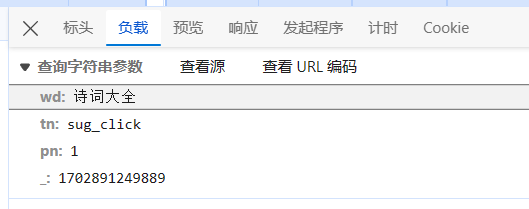
wd 是 包含的关键字的所有词语,pn表示页码,其他参数不是很重要,实际测试发现,不设置也返回,这里建议保留你浏览器生成的默认参数。
在mysql中建如下表格
CREATE TABLE `single_character_info` (
`pinyin` varchar(255) CHARACTER SET utf8mb4 NOT NULL,
`word` varchar(255) NOT NULL,
`plainPinyin` varchar(255) CHARACTER SET utf8mb4 NOT NULL,
`definition` varchar(4096) CHARACTER SET utf8mb4 DEFAULT NULL,
`pronunciation` varchar(255) DEFAULT NULL,
`wordID` int DEFAULT NULL,
PRIMARY KEY (`word`,`pinyin`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
准备单个词典文件
下载地址:BaiduPinyinCrawler/data/clover.base.dict.yaml at main · SivanLaai/BaiduPinyinCrawler (github.com)
安装python对应安装包
certifi==2022.6.15
charset-normalizer==2.1.1
idna==3.3
PyMySQL==1.0.2
requests==2.28.1
six==1.16.0
urllib3==1.26.12
代码实现
日志模块
# Logger.py
import logging, logging.handlers, time, os
from Config import config
class Log(object):
"""
logging的初始化操作,以类封装的形式进行
"""
# 设置输出的等级
LEVELS = {
"NOSET": logging.NOTSET,
"DEBUG": logging.DEBUG,
"INFO": logging.INFO,
"WARNING": logging.WARNING,
"ERROR": logging.ERROR,
"CRITICAL": logging.CRITICAL,
}
log_level = config['LOG']['LEVEL']
def __init__(self):
# 定义对应的程序模块名name,默认为root
self.logger = logging.getLogger()
# 每次被调用后,清空已经存在handler
self.logger.handlers.clear()
# log_path是存放日志的路径
service_name = "FundCrawler"
timestr = time.strftime("%Y_%m_%d", time.localtime(time.time()))
lib_path = config['LOG']['LOG_PATH']
# 如果不存在这个logs文件夹,就自动创建一个
if not os.path.exists(lib_path):
os.mkdir(lib_path)
# 日志文件的地址
self.logname = lib_path + "/" + service_name + "_" + timestr + ".log"
# 必须设置,这里如果不显示设置,默认过滤掉warning之前的所有级别的信息
self.logger.setLevel(self.log_level)
# 日志输出格式
self.formatter = logging.Formatter(
"[%(asctime)s] [%(levelname)s]: %(message)s"
) # [2019-05-15 14:48:52,947] - test.py] - ERROR: this is error
# 创建一个FileHandler, 向文件logname输出日志信息
# fh = logging.FileHandler(self.logname, 'a', encoding='utf-8')
fh = logging.handlers.RotatingFileHandler(
filename=self.logname, maxBytes=1024 * 1024 * 50, backupCount=5
)
# 设置日志等级
fh.setLevel(self.log_level)
# 设置handler的格式对象
fh.setFormatter(self.formatter)
# 将handler增加到logger中
self.logger.addHandler(fh)
# 创建一个StreamHandler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(self.log_level)
ch.setFormatter(self.formatter)
self.logger.addHandler(ch)
# # 关闭打开的文件
fh.close()
def info(self, message):
self.logger.info(message)
def debug(self, message):
self.logger.debug(message)
def warning(self, message):
self.logger.warning(message)
def error(self, message):
self.logger.error(message)
def critical(self, message):
self.logger.critical(message)
global logger
logger = Log()
配置模块
# Config.py
import configparser
import sys
global config
config = configparser.ConfigParser()
config.sections()
config.read("setting.ini")
配置文件
[LOG]
LEVEL = INFO //日志等级
LOG_PATH = ./FundCrawler/logs //日志目录
[MYSQL]
host = 127.0.0.1 //MYSQL服务器ip
PORT = 20137 //MYSQL服务器端口
USERNAME = username
PASSWORD = password
DATA_BASE_NAME = Fund
爬虫主程序
# PinyinDataCrawler.py
import random
import requests
import json
import pymysql
from Logger import logger
from Config import config
header_str = '''Host:hanyu.baidu.com
Connection:keep-alive
sec-ch-ua:"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"
Accept:application/json, text/javascript, */*; q=0.01
X-Requested-With:XMLHttpRequest
sec-ch-ua-mobile:?0
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67
Sec-Fetch-Site:same-origin
Sec-Fetch-Mode:cors
Sec-Fetch-Dest:empty
Referer:https://hanyu.baidu.com/s?wd=%E5%8F%B7%E8%AF%8D%E7%BB%84&from=poem
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7
Cookie:填写自己的Cookie'''
params_str = '''wd=%E5%8F%B7%E8%AF%8D%E7%BB%84
from=poem
pn=1
_=1628826451938'''
class PinyinDataCrawler:
homographWeightDict = dict()
def __init__(self):
self.conn = self.getConnection()
self.character_list = self.getAllCharacters()
f = open("./data/luna_pinyin.dict.yaml", "r", encoding='utf8')
for line in f.readlines():
datas = line.strip().split('\t')
if len(datas) == 3:
word = datas[0]
pinyin = datas[1]
weight = datas[2]
if word not in self.homographWeightDict:
self.homographWeightDict[word] = dict()
if pinyin not in self.homographWeightDict[word]:
self.homographWeightDict[word][pinyin] = dict()
self.homographWeightDict[word][pinyin] = weight
def getHomograph(self, word="不"):
return self.homographWeightDict.get(word, dict())
# 把所有的多音字进行识别
def splitHomograph(self, path='./Clover四叶草拼音', newPath='./Clover四叶草拼音new'):
if not os.path.exists(newPath):
os.mkdir(f'{newPath}')
for file_now in os.listdir(path):
new_file_path = os.path.join(newPath, file_now)
curr_path = os.path.join(path, file_now)
new_file = open(new_file_path, 'w', encoding="utf-8")
if 'base' not in curr_path:
continue
for line in open(curr_path, encoding='utf-8'):
if "\t" in line:
keyword = line.split('\t')[0]
pinyin_old = line.split('\t')[1].strip()
count_str = line.split('\t')[-1].strip().replace(" ", '')
pinyinDict = self.getHomograph(keyword)
if len(pinyinDict) == 0:
new_file.write(line)
new_file.flush()
else:
currPinyins = sorted(pinyinDict.items(), key=lambda x: x[1], reverse=True)
for currPinyin in currPinyins:
try:
newLine = line.replace(pinyin_old, currPinyin[0]).replace(count_str, currPinyin[1])
new_file.write(newLine)
new_file.flush()
except Exception as e:
print(e)
else:
new_file.write(line)
new_file.flush()
new_file.close()
def format_header(self, header_str=header_str):
header = dict()
for line in header_str.split('\n'):
header[line.split(':')[0]] = ":".join(line.split(':')[1:])
return header
def format_params(self, params_str=params_str):
params = dict()
for line in params_str.split('\n'):
params[line.split('=')[0]] = line.split('=')[1]
return params
def getPlainPinyin(self, sug_py):
splits = ['a', 'o', 'e', 'i', 'u', 'ü']
shengdiao = '''a ā á ǎ à
o ō ó ǒ ò
e ē é ě è
i ī í ǐ ì
u ū ú ǔ ù
ü ǖ ǘ ǚ ǜ'''
shengdiaoToWord = dict()
for line in shengdiao.split("\n"):
datas = line.split(' ')
for curr in datas[1:]:
shengdiaoToWord[curr] = datas[0]
plain_pinyin = ''
for curr in sug_py:
if curr not in shengdiaoToWord:
plain_pinyin += curr
else:
plain_pinyin += shengdiaoToWord[curr]
return plain_pinyin
def storeWord(self, word, currMean, word_index):
try:
pinyin = currMean.get("pinyin", "")
if len(pinyin) > 0:
pinyin = pinyin[0]
definition = currMean.get("definition", "")
if len(definition) > 0:
definition = "\n".join(definition).replace("'", '"')
if len(definition) > 4096:
definition = definition[:4096]
plain_pinyin = currMean.get("sug_py", "")
if len(plain_pinyin) > 0:
plain_pinyin = self.getPlainPinyin(pinyin)
pronunciation = currMean.get("tone_py", "")
if len(pronunciation) > 0:
pronunciation = pronunciation[0]
sql_str = f"insert into single_character_info values ('{pinyin}', '{word}', \
'{plain_pinyin}', '{definition}', '{pronunciation}', {word_index})"
cursor = self.conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
self.conn.commit()
except Exception as e:
if "Duplicate" not in f"{e}":
logger.error(f"word: {word}, pinyin: {pinyin}, error_info: {e}")
def fixesDatas(self):
f = open('1.txt')
for line in f.readlines():
word = line.replace(" ", "").split(":")[-3].split(",")[0]
logger.info(f"更新词组[{word}]的数据")
headers = self.format_header()
params = self.format_params()
params["pn"] = 1
url = "https://hanyu.baidu.com/hanyu/ajax/search_list"
params['wd'] = word
while True:
try:
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 10))
break
except Exception as e:
logger.error(f"error_info: {e}")
if 'timed out' in f"{e}":
continue
datas = json.loads(response.text).get('ret_array', list())
for currWordData in datas:
if 'mean_list' not in currWordData:
logger.warning(f"warning_info: {word} has not mean_list")
continue
currMeanList = currWordData["mean_list"]
try:
word = currWordData["name"][0]
for currMean in currMeanList:
self.storeWord(word, currMean, 0)
break
except Exception as e:
logger.error(f"error_info: {e}")
def parserDatas(self, word, datas, word_index):
for currWordData in datas:
if 'mean_list' not in currWordData:
logger.warning(f"warning_info: {word} has not mean_list")
continue
currMeanList = currWordData["mean_list"]
word = currWordData["name"][0]
for currMean in currMeanList:
self.storeWord(word, currMean, word_index)
def getConnection(self):
host = config["MYSQL"]["HOST"]
port = int(config["MYSQL"]["PORT"])
db = config["MYSQL"]["DATA_BASE_NAME"]
user = config["MYSQL"]["USERNAME"]
password = config["MYSQL"]["PASSWORD"]
conn = pymysql.connect(host=host, port=port, db=db, user=user, password=password)
return conn
def getCurrWordPageCount(self, url, params, headers):
pageCount = -1
while pageCount == -1:
try:
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 27))
if len(response.text) == 0:
break
pageDatas = json.loads(response.text).get('extra', dict())
pageCount = pageDatas.get("total-page", 0)
except Exception as e:
logger.error(f"getCurrWordPageCount, error_info: {e}")
time.sleep(random.randint(5, 10))
logger.info(f"getCurrWordPageCount, pageCount = {pageCount}")
return pageCount
def crawlerExactPhrasePinyin(self, word="号", word_index=0, characters=None, phrase=True):
if characters is None and phrase is True:
characters = self.character_list
if characters is None:
characters = list()
headers = self.format_header()
params = self.format_params()
params["pn"] = 1
url = "https://hanyu.baidu.com/hanyu/ajax/search_list"
if phrase:
params['wd'] = word + "词组"
else:
params['wd'] = word
pageCount = self.getCurrWordPageCount(url, params, headers)
currPageIndex = 0
while currPageIndex < pageCount:
params["pn"] = currPageIndex
while params["pn"] == currPageIndex:
try:
logger.info(f"更新汉字[{word}]({word_index + 1} / {len(characters)})的词组数据(页数:{currPageIndex + 1} / {pageCount}) ")
response = requests.get(url, params=params, headers=headers, timeout=(3.05, 10))
datas = json.loads(response.text).get('ret_array', list())
self.parserDatas(word, datas, word_index)
currPageIndex += 1
except Exception as e:
logger.error(f"更新汉字{word}出现错误, 错误信息: {e}")
time.sleep(random.randint(5, 9))
time.sleep(random.randint(5, 100) * 0.01)
logger.info(f"更新汉字[{word}]的词组数据完成。")
def getAllCharacters(self):
file_path = './data/clover.base.dict.yaml'
file = open(file_path, 'r', encoding="utf-8")
character_list = list()
for line in file.readlines():
if '\t' in line:
word = line.split('\t')[0]
if word not in set(character_list):
character_list.append(word)
return character_list
def getCurrCharacterStoreIndex(self):
sql_str = 'select * from single_character_info order by wordID desc'
cursor = self.conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_str)
data = cursor.fetchone()
logger.info(f'getCurrCharacterStoreIndex data = {data}')
if data is None:
return 0
return data['wordID']
def crawlerPhraseDict(self):
characters = self.character_list
i = self.getCurrCharacterStoreIndex()
#i = 41318
while i < len(characters):
word = characters[i]
logger.info(f'开始更新汉字[{word}]({i + 1}/{len(characters)})的数据...')
self.crawlerExactPhrasePinyin(word, i, characters)
i = i + 1
logger.info(f'更新汉字[{word}]({i + 1}/{len(characters)})的数据完成!')
time.sleep(random.randint(1, 5) * 0.2)
if __name__ == "__main__":
PinyinDataCrawler().crawlerPhraseDict()
- 注意事项
- 需要把header_str中的Cookie替换成你电脑浏览器生成的Cookie
- 主程序中为了防止被ban加入了随机时间暂停的功能,不要轻易修改这部分,以防自己账号被封禁
- 数据量比较多,大概有35W的数据,又有随机暂停,所以需要抓取2-3天左右,建议后台运行
运行程序
运行日志(部分展示)

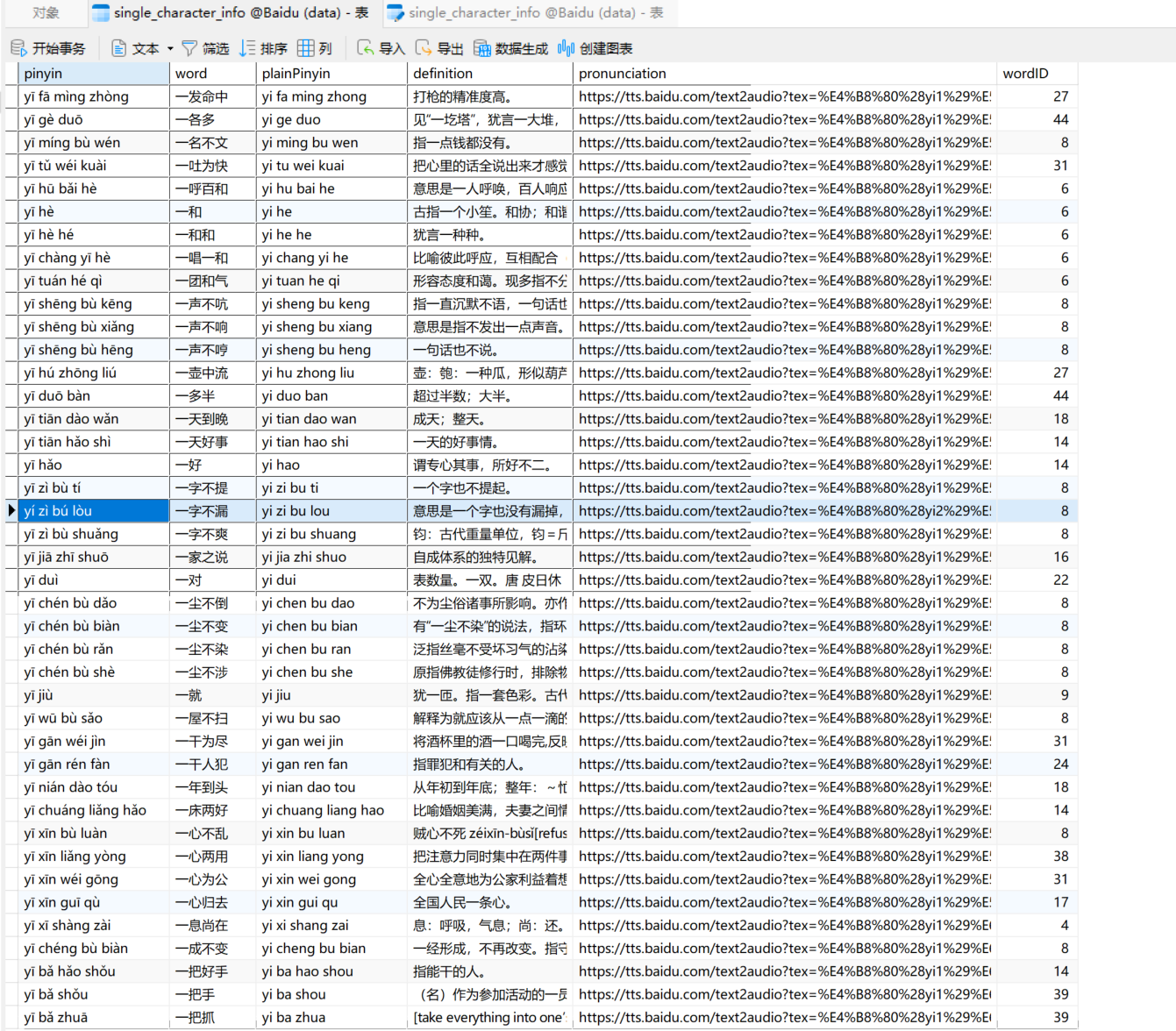
数据库存储(部分展示)

 吾爱游客
发表于 2023-12-16 08:54
吾爱游客
发表于 2023-12-16 08:54
 发表于 2023-12-18 11:58
发表于 2023-12-18 11:58