0x00. 一切开始之前
Linux kernel exploitation 方向的论文虽然数量极少,但能上顶会的大部分都还挺有意思的,尤其是发在 USENIX 2023 上的这一篇论文笔者觉得是非常有实战价值的(笑),因此这里简单做个阅读笔记
Abstract
攻击的隐秘性对于攻击者而言是最为至关重要的,因为一旦攻击被发现就寄了,但由于 SLUB 分配器的构造的缘故成功完成漏洞利用的概率都较低
这篇论文提出 Pspray :一项基于时序侧信道的漏洞利用技术,经测试这项技术可以显著提高漏洞利用的成功率
0x01. Introduction
没必要讲.jpg
Linux kernel 有着如 KCFI、KASLR、KDFI 在内的多种保护措施,这使得攻击者难以成功完成利用
对攻击者而言攻击的隐秘性是最重要的需求之一,若攻击失败则将会被防守方发现,因为这通常会留下痕迹(例如 kernel panic),因此攻击者非常需要提高攻击的成功率
内核漏洞大都为堆上漏洞(例如由 syzkaller 找到的 1107 个漏洞中有 968 个都是堆相关的),而对攻击者而言要完成利用十分困难,因为这需要攻击者能预测当前的堆分配器状态,而内核堆管理器 SLUB 的结构使其难以被完成
这里原论文还举了个例子,笔者就不摘抄了,毕竟看这篇论文的前提肯定是默认读者都是会点 kernel pwn 的,不会 kernel pwn 你看这篇论文干啥嘛
本文提出一种名为 $PSPRAY$ 的新的内核堆利用手法,其可以显著地提升对抗 slab freelist 随机化等保护措施的堆利用的成功率,更具体地说, $PSPRAY$ 的核心是使用时序侧信道来间接获取 slab 的分配状态
本文工作总结如下:
- 分析了堆利用的失败情况
- 新的堆利用技术
- 新的防御技术
0x02. Background
2.1 SLUB allocator
可以参考笔者的这篇博客
The architecture of SLUB allocator
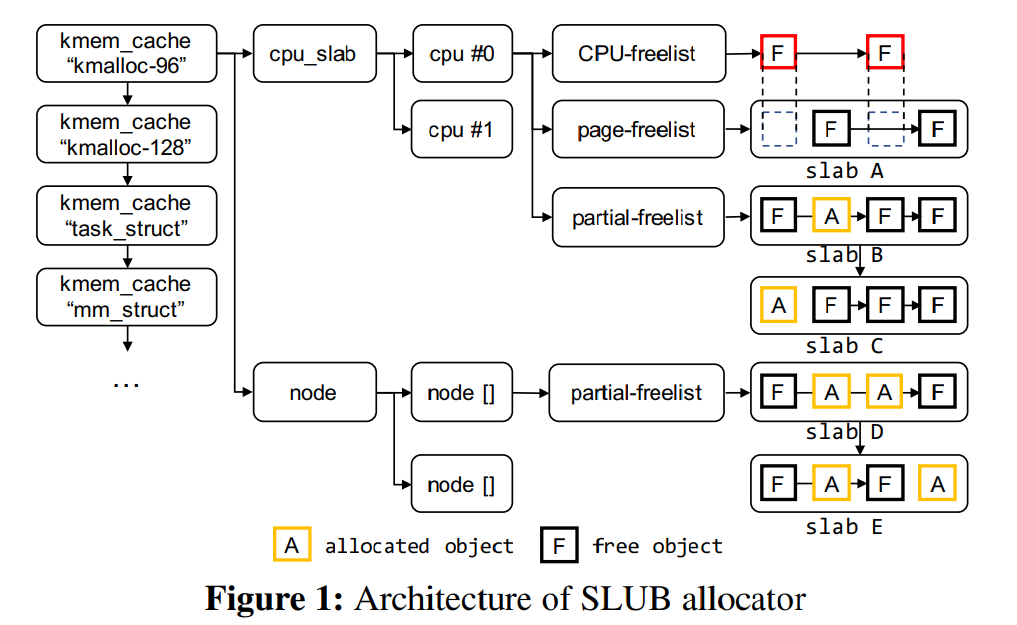
SLUB 是 Linux kernel 默认的堆分配器,其基本结构如图 1 所示,其包含了多个不同类型与尺寸的 kmem_cache 内存池,每个 kmem_cache 都有一个 per-CPU 内存池,其中包含独立的 freelist 、page 、partial ,freelist 为一个基于 page 页面上空闲对象所组成的单向链表
除了 freelist 以外,每个 slab 都有自己独立的 freelist ;除了 CPU partial page freelist 以外,每个 node 也有自己独立的 CPU partial page freelist ,在 CPU partial page freelist 用完之后启用
Allocation sequence of SLUB allocator
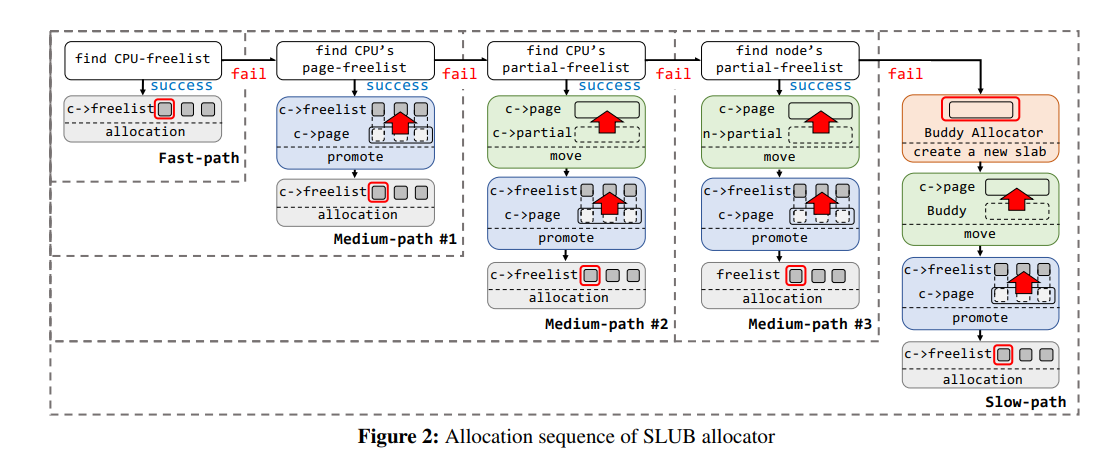
图 2 展示了 SLUB 的分配流程:
- 首先尝试从
CPU freelist 上取
CPU-freelist 为空,尝试从 CPU page 上取 freelist,给回 CPU freelist (可以理解为 percpu freelist 的初始化)CPU-page 也空了,尝试从 CPU partial 链表上取CPU partial 链表也空了,尝试从 NODE partial 链表上取NODE partial 链表也空了,只好转向 Buddy System 请求分配新的内存页
buddy system 也空了就该 OOM kill 了
2.2 Slab Freelist Random
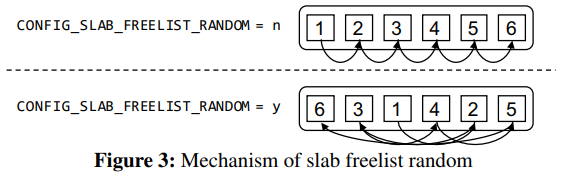
简单来说就是 CONFIG_SLAB_FREELIST_RANDOM 这个保护的开启会使得 freelist 的初始化更加随机化,空闲对象链表连接不再按常规的地址顺序连接,而是会被打乱
0x03. Exploitation method and failure cases
本节主要讲常规的漏洞利用手法
3.1 Out-Of-Bounds
Exploitation method
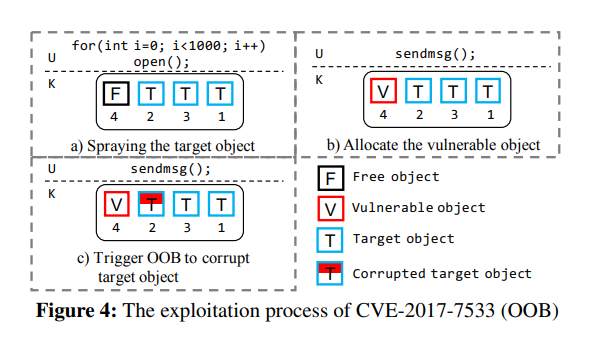
OOB 就是越界读写,通常来说我们需要在漏洞对象后面放一个被溢出的目标对象,最简单的做法就是直接堆喷就完事了
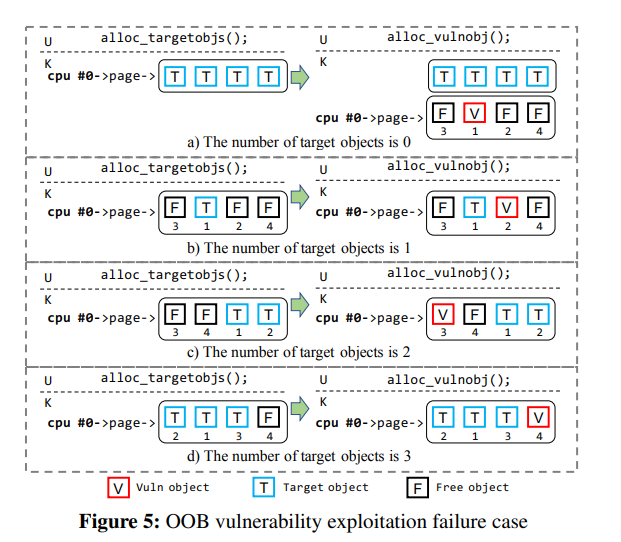
Failure cases
但因为地址随机化的存在,我们的被溢出目标对象不一定能恰好落在漏洞对象后面,中间可能隔了几个对象或者直接就错位了:(
Probability model
在开启 freelist 随机化之后的漏洞利用成功率如下,基于 Linux kernel 使用 Fisher-Yates shuffle 算法来进行随机化这个前提计算的,其中 $N$ 为一张 slub 上的总对象数,同时我们假设在同一张 slab 上分配了 1 个漏洞对象与 $k$ 个 victim 对象:
\frac{ _{N-1} C _{k}* _{k} C _{1}}{ _{N} C _{k} * _{N-k} C _{1}} = \frac{k}{N}
总体而言,我们从 $N$ 个空闲对象中选择 $k$ 个 victim 对象 与 1 个漏洞对象,在进行利用时 victim 对象与漏洞对象必须相邻,因此我们从 $N-1$ 个对象中取出 $k$ 个对象(剩余一个作为漏洞对象),喷射的 victim 对象数量可以从 0 到 $N-1$ ,因此对于带有 random slab freelist 的 OOB 利用而言的成功率计算如下:
P_{OOB}^{Baseline}=\frac{\sum_{k=0}^{N-1}\frac{k}{N}}{N}=\frac{N-1}{2N}
3.2 Use-After-Free and Double-Free
UAF exploitation method
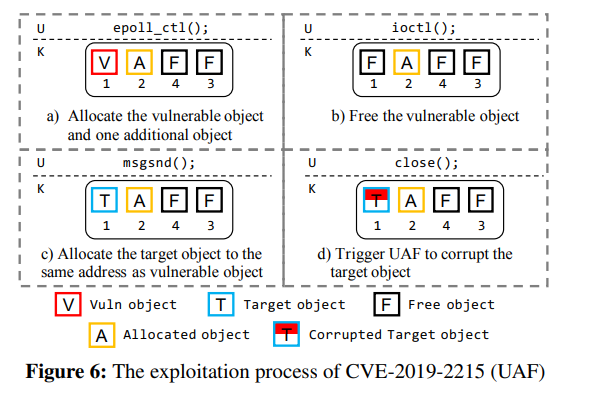
UAF 漏洞的利用通常是要将漏洞对象与 victim 对象放在同一内存地址,图 6 展示了对 CVE-2019-2215 的利用过程,首先用 epoll_ctl() 分配漏洞对象,接下来用 ioctl() 释放漏洞对象,随后用 msgsnd() 取回刚刚释放的对象,最后再用 close() 将该对象释放
DF exploitation method
在笔者看来 DF 和 UAF 本质上是一样的
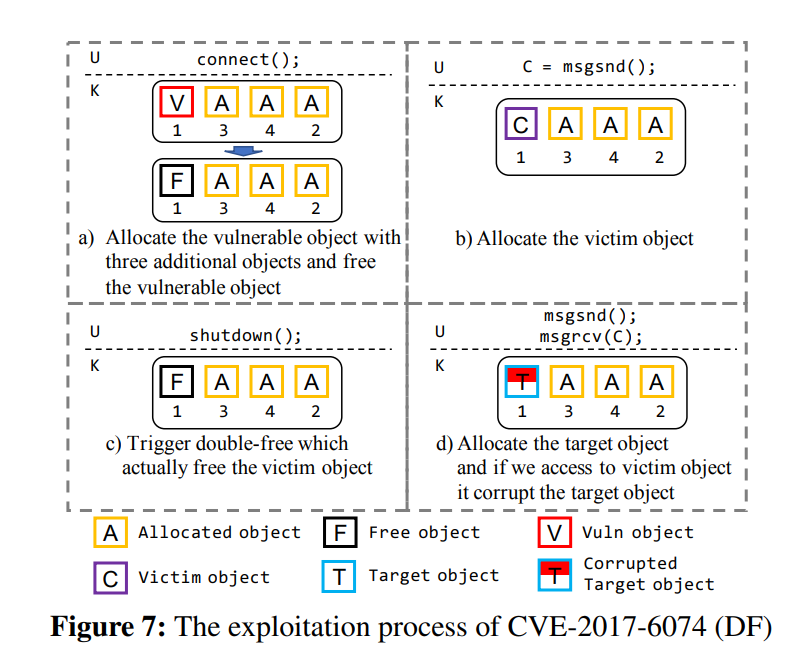
Double Free 漏洞则是将一个已经被释放的对象再次释放,从而通过留下的垂悬指针完成利用(笔者注:其实就是 UAF 嘛),图 7 展示了对 CVE-2017-6074 的利用过程,首先通过 connect() 分配漏洞对象与三个额外的对象冰释放掉漏洞对象,随后通过 msgsnd() 分配 victim 对象,接下来通过 shutdown() 完成 DF 将 victim 对象释放掉,最后分配目标对象,当我们访问 victim 对象时目标对象便会被破坏
Failure cases
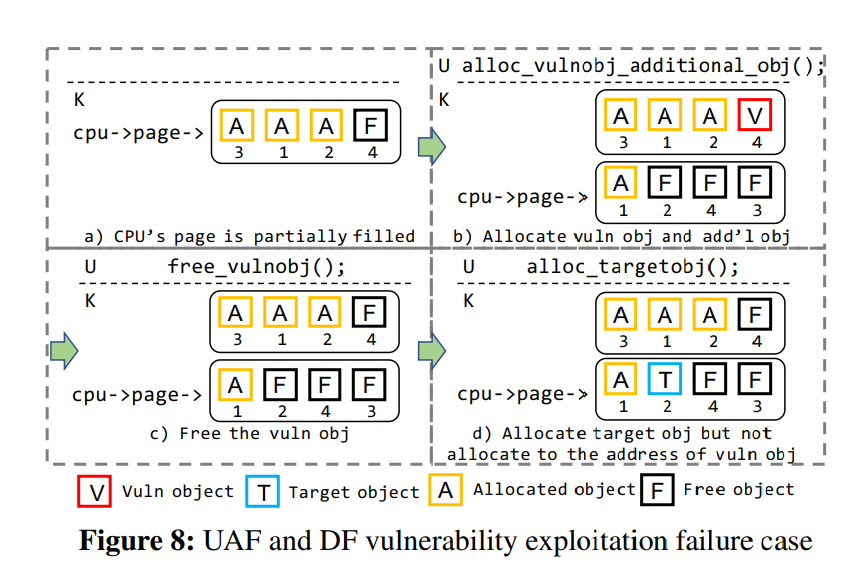
由于 SLUB 的特性,对 UAF 与 DF 漏洞的利用是有可能失败的,图 8 显示了利用 UAF/DF 漏洞失败的一种可能性,即额外的“噪声”分配导致了 perCPU page 发生了改变
笔者注:比如说 key_ctl 这样的
Probability model
UAF 与 DF 漏洞利用的成功率如下,$N$ 为每张 slab 上的对象数量, $A$ 为系统调用所分配的对象数量(即分配的漏洞对象数量与额外结构体的数量之和):
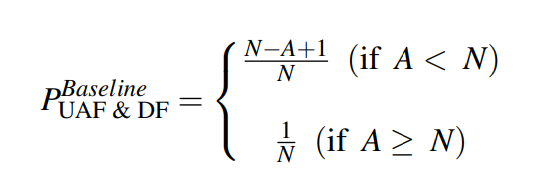
有两种情况:当 A < N 时,成功率决定于漏洞对象与额外对象是否在同一张 slab 上;当 A >= N 时,当分配漏洞对象的系统调用所分配的最后一个对象完全填充 CPU page 时利用将会成功,若一张 slab 被耗尽,对应的 slab 会被移动到 full 链表上,CPU page 便变为空,此时若对象被释放,则包含该对象的 slab 将重新变为 CPU page
0x04. Our Approach : PSPRAY
漏洞利用失败的主要原因是对 slab 信息的缺失,本文找到了一种能够获取 slab 的部分分配信息的时序侧信道方法,从而提高利用成功概率
4.1 Timing Side-Channel on SLUB allocator
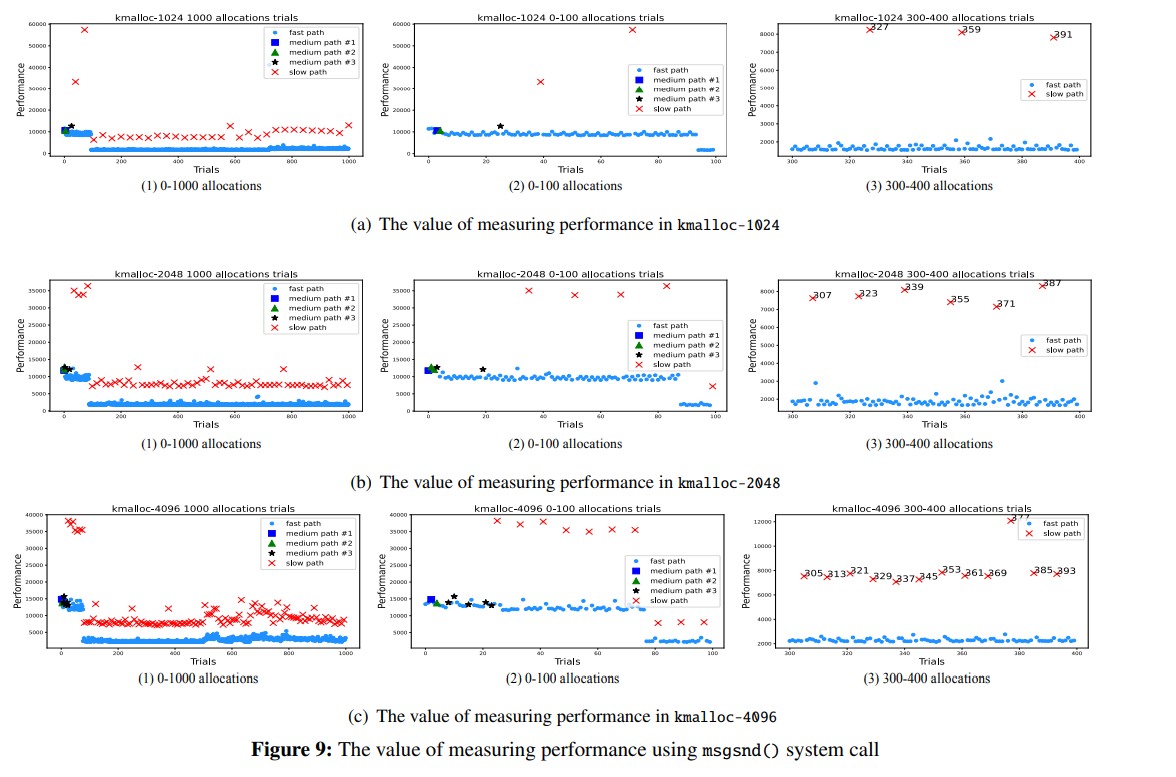
如图 2.1 所示,SLUB 有五条不同深度的分配路径以优化性能表现,为了弄清不同路径的表现,作者通过 msgsnd() 系统调用(如图 4.3 所示其仅分配一个对象)测试了从 kmalloc() 的核心函数 slab_alloc_node() 的开始到结尾的性能,经过多轮测试发现 slow-path 与其他路径相比存在明显的表现差距,因此攻击者可以通过测量分配时间得知内存分配所经历的路径
4.2 Inferring Allocation Status
slow-path 以外的分配路径的分配状态都是难以确定的,但 slow-path 的行为与其他路径不同,此时内核会从 buddy system 分配一张新 slab,由此我们可以知道当前的 slab 刚被分配且仅分配了一个对象
4.3 Proof-Of-Concept
Finding an adequate system call
为了使用时序侧信道,我们需要找到满足以下三个条件的系统调用:
- 普通用户权限可用
- 仅分配一个对象
- 除了对象分配以外的性能开销要小
作者修改了 kernel 以在系统调用仅分配一个 kmalloc-xx 中的对象时 panic,并使用 Syzkaller 进行测试,找到了如表 A.1 所示的 23 个满足该条件的系统调用,这些从用户空间拷贝数据的系统调用涵盖了 kmalloc-32 到 kmalloc-8192,同时其内存分配以外的代码不会过于影响内存

Experiment
简单来说就是用 msgsnd() 做了堆喷 1000 次的测试并测量其表现
Experiment Results
图 9 为使用 msgsnd() 进行测试的结果,可知 fast-path 与 medium-path 间难以做出区分(都要消耗 10000 左右的 CPU 周期),但 slow-path 可以被区分(要消耗 35000 左右的 CPU 周期)
0x05. Application of PSPRAY
5.1 OOB Exploitation
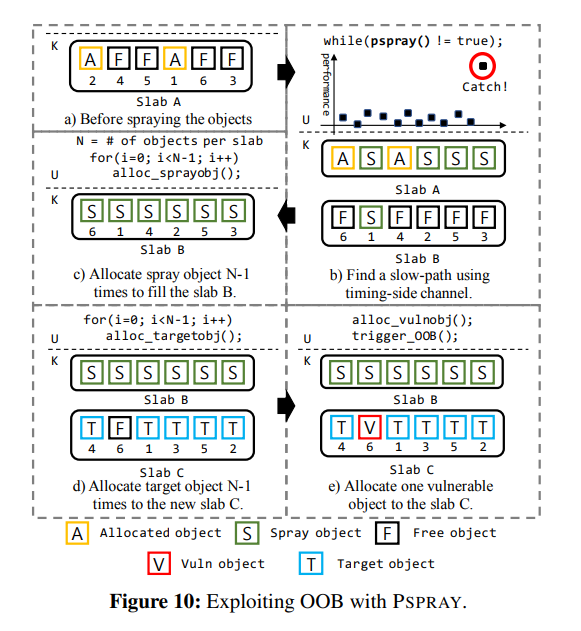
图 10 展示了在开启 free list randomization 的情况下对 OOB 漏洞应用 PSPRAY 的过程:
- 使用 PSPRAY 确定
slow-path 是否被执行,此时 slab B 被创建且已分配了一个结构体
- 接下来我们堆喷
N-1 个对象将其完全分配(假设一张 slab 上有 N 个对象)
- 我们接下来的分配又会分配一张新的 slab
C ,分配 N - 1 个 victim 对象
- 分配漏洞对象,此时若漏洞对象不为 slab 上地址最高处对象,则 OOB 将成功
利用成功率为:
P_{OOB}^{PSPRAY}=\frac{N-1}{N}
5.2 UAF and DF Exploitation
图 11 展示了如何在 UAF 与 DF 漏洞上利用 PSPRAY:
- 首先用 PSPRAY 找到新 slab 被分配的时间点,此时我们便知道一张已分配一个对象的 slab 被创建了
- 然后正常利用 UAF/DF

利用成功率为:
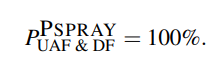
0x06. Attack Evaluation
论文里这一节主要是做测试
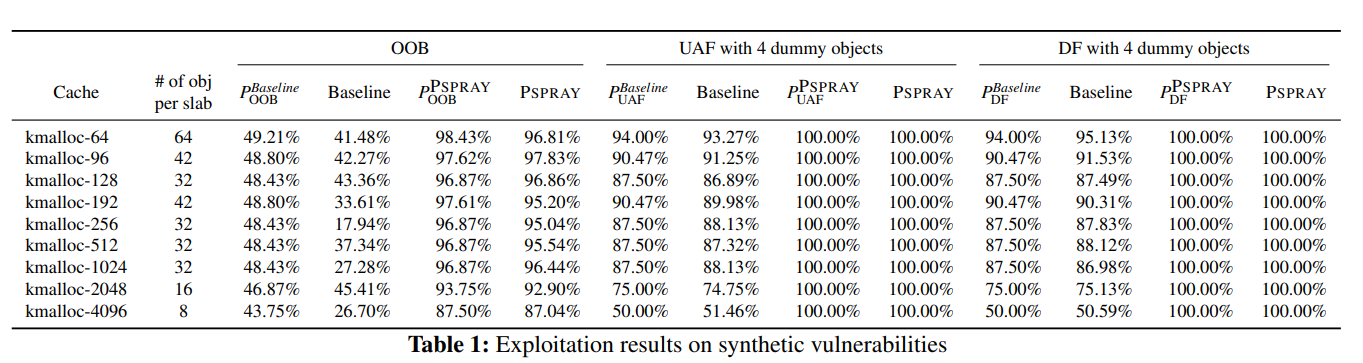
6.1 Synthetic Vulnerability
主要是作者自己开发漏洞自己打,测试用的 OOB 洞长这个样子:

UAF 洞长这个样子:

结果如表 1 所示:
6.2 Real-World Vulnerability
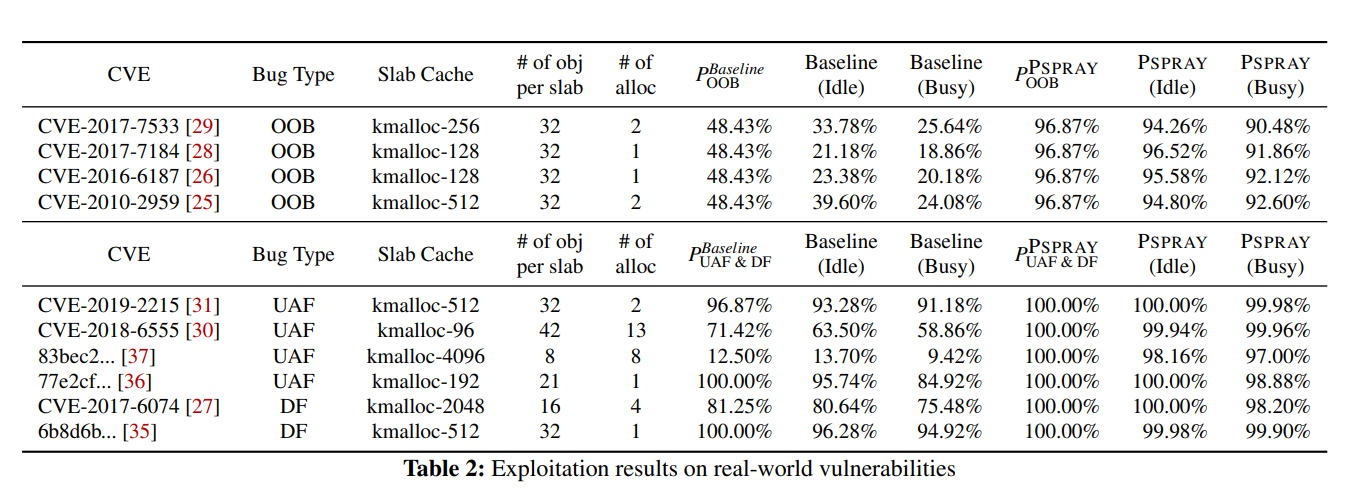
打了一些真实的洞,结果如表 2 所示,和公开的 exp 相比利用成功率提升明显:
0x07. Mitigation
PSPRAY 主要有两个点:
slow-path 的分配速度差异明显slow-path 的出现意味着此时的 freelist 为空
作者认为针对 PSPRAY 的防御手段主要有以下两个:
- 让所有的分配路径都有着相似的性能表现(针对第一个点)
- 随机化
slow-path 分配上下文(针对第二个点)
基本没啥活可以整
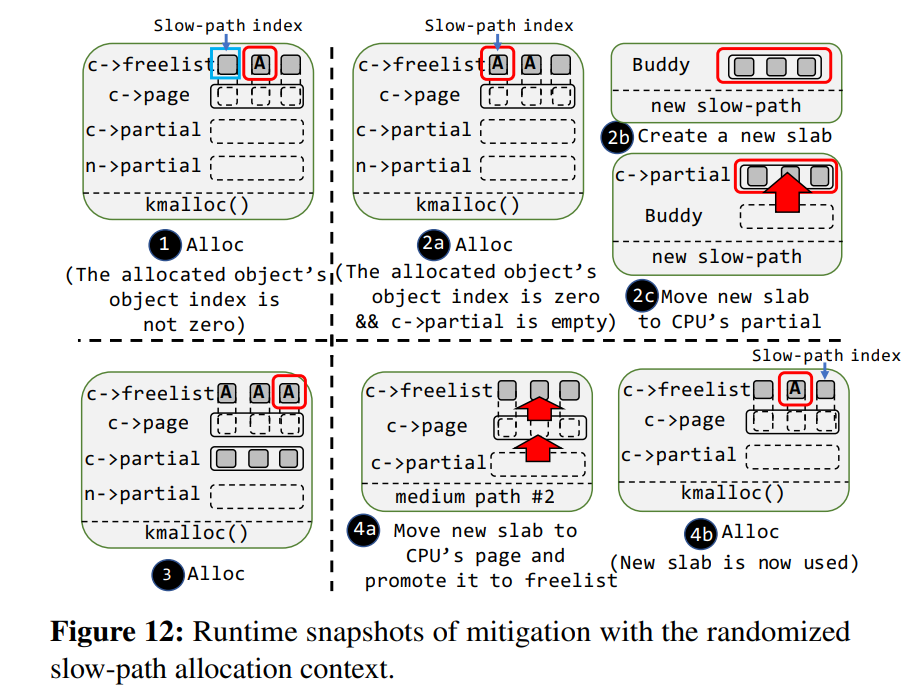
Mitigation #2. Randomized Slow-path Allocation Context.
主要是让分配并不是在 freelist 为空时才进入到 slow-path ,这里设计了一个简易的算法就是让 slab 上对象的 idx 与一个常量相等且 CPU partial 为空时进到一个新的 slow path,从而使得这两个 slow path 无法被区分

图 12 显示了这种方法的基本原理:
0x08. Discussion
8.1 The Noise
由调度器带来的噪音仍可以阻碍利用,主要来自两种机制:CPU 迁移与上下文切换;这样的噪声可以在分配/释放一个目标对象或漏洞对象时出现
笔者感觉用 sched_setaffinity() 绑核可以完美解决这个问题
8.2 The Other OSes
其他的 OSes 也可以采用 PSPRAY 方法进行利用,因为其采用与 Linux 相类似的堆分配器,作者这里测了 FreeBSD 和 XNU,具体的笔者就不贴了:)
Kernel Automated Exploit Generation
自动化利用,如 FUZE 用 fuzz 和符号执行来构造利用,KOOBE 则针对 OOB 类漏洞进行自动化利用生成
AEG 说实话还是挺有意思的,可惜笔者之前确实没咋关注过:)
Kernel Exploit Techniques
类似的利用技术相关的研究有 ret2usr、ret2dir、ExpRace、Eloise 等
Timing Side-Channel Attack against Kernel
对时序侧信道技术的研究也很多,比如说 https://ieeexplore.ieee.org/document/6547110、DRK、Meltdown 等
0xFF. What's more?
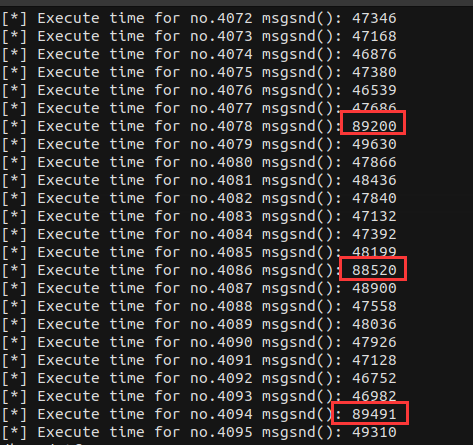
笔者自己也试了一下这个方法,发现slow-path 的执行时间确实可以与其他路径进行区分(只需要用一些统计学手段就好),下面是笔者自己测试用的代码,在真机测试与 QEMU 虚拟机测试中 slow-path 都表现出了显著的性能开销,这意味着这种方法确乎可以被应用于 CTF 与实战当中:
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdint.h>
#include <sched.h>
#include <sys/msg.h>
#include <sys/ipc.h>
struct list_head {
uint64_t next;
uint64_t prev;
};
struct msg_msg {
struct list_head m_list;
uint64_t m_type;
uint64_t m_ts;
uint64_t next;
uint64_t security;
};
struct msg_msgseg {
uint64_t next;
};
int get_msg_queue(void)
{
return msgget(IPC_PRIVATE, 0666 | IPC_CREAT);
}
int read_msg(int msqid, void *msgp, size_t msgsz, long msgtyp)
{
return msgrcv(msqid, msgp, msgsz, msgtyp, 0);
}
int del_msg_queue(int msqid)
{
struct msqid_ds ds_buf;
return msgctl(msqid, IPC_RMID, &ds_buf);
}
/**
* the msgp should be a pointer to the `struct msgbuf`,
* and the data should be stored in msgbuf.mtext
*/
int write_msg(int msqid, void *msgp, size_t msgsz, long msgtyp)
{
((struct msgbuf*)msgp)->mtype = msgtyp;
return msgsnd(msqid, msgp, msgsz, 0);
}
/* to run the exp on the specific core only */
void bind_cpu(int core)
{
cpu_set_t cpu_set;
CPU_ZERO(&cpu_set);
CPU_SET(core, &cpu_set);
sched_setaffinity(getpid(), sizeof(cpu_set), &cpu_set);
}
uint64_t rdtsc(void)
{
uint32_t lo, hi;
asm volatile (
"rdtsc" : "=a" (lo), "=d" (hi)
);
return (((uint64_t) hi) << 32) | lo;
}
int main(int argc, char **argv, char **envp)
{
int msqid[0x1000];
uint64_t exec_time[0x1000];
char buf[0x1000];
bind_cpu(0);
for (int i = 0; i < 0x1000; i++) {
msqid[i] = get_msg_queue();
if (msqid[i] < 0) {
printf("[x] FAILD to get %d msg_queue!\n", i);
perror("FAILED to get msg_queue");
exit(EXIT_FAILURE);
}
}
*(size_t*) buf = 123456;
for (int i = 0; i < 0x1000; i++) {
uint64_t begin, end;
begin = rdtsc();
if (write_msg(msqid[i],buf,512-sizeof(struct msg_msg),0xdeadbeef) < 0) {
printf("[x] FAILD to send %d msg!\n", i);
perror("FAILED to alloc msg_msg");
exit(EXIT_FAILURE);
}
end = rdtsc();
exec_time[i] = end - begin;
}
for (int i = 0; i < 0x1000; i++) {
if (read_msg(msqid[i],buf,512-sizeof(struct msg_msg),0xdeadbeef) < 0) {
printf("[x] FAILD to read %d msg!\n", i);
perror("FAILED to free msg_msg");
exit(EXIT_FAILURE);
}
}
for (int i = 0; i < 0x1000; i++) {
if (del_msg_queue(msqid[i]) < 0) {
printf("[x] FAILD to delete %d msg_queue!\n", i);
perror("FAILED to free msg_queue");
exit(EXIT_FAILURE);
}
}
for (int i = 0; i < 0x1000; i++) {
printf(" Execute time for no.%d msgsnd(): %ld\n", i, exec_time[i]);
}
return 0;
}
结果其实还是挺明显的,不过需要注意的是主流发行版的 kmalloc-512 的 slab 大小和我们平时打CTF 用的内核的不一定一样
笔者真机环境这个是 16 个 512 对象一张 slab,CTF 环境通常是 8 个512 对象一张 slab
不过在笔者看来我们其实并没有必要使用 PSPRAY 方法进行利用,即没有必要手动获取分配新的 slab 页面的时间,还是以 OOB 堆喷为例,当堆喷到一定数量级的时候其实都会向 buddy system 请求新的页面,那我们可以简单拆为如下四段式利用:
- 首先堆喷大量同大小对象耗空 partial slab,迫使 SLUB 请求新页
- 堆喷目标对象,让 SLUB 再取新页
- 分配漏洞对象
- 堆喷目标对象,让 SLUB 再取新页
这种方法本质上与 PSPRAY 所达成的效果一致,因为实质上我们并不需要判断新 slab 页面的分配时间,只需要达成使用目标对象将漏洞对象包裹的效果即可,这也是笔者所常用的利用技巧之一 :)
参见笔者出的一道 CTF 题目:D^3CTF2023 - d3kcache,里面便使用了这种方法进行辅助
不过无论如何,这篇论文的作者确乎向我们展示了一种非常有趣且相对实用的漏洞利用技巧,让笔者受益匪浅

 [复制链接]
[复制链接]

 发表于 2023-9-17 20:19
发表于 2023-9-17 20:19
 |
发表于 2023-9-18 21:14
|
发表于 2023-9-18 21:14







