文章没有多大的技术含量,只是尽量详细地列出步骤,给予想学但是没有入门的同学一个参考,毕竟天才/大牛也是从 1+1 开始的,所以叫“小白教小白”
因为本人是第一次学,也只体验过文中列出的这一个案例,所以叫“初探”
最近在看一本反爬虫的书,记录一下学习内容。既为体验一遍完整的过程,加深记忆;也为分享知识,互相学习,共同进步
希望通过此文建立看书我会、我说你会的知识传播链
学情导入
研究过程
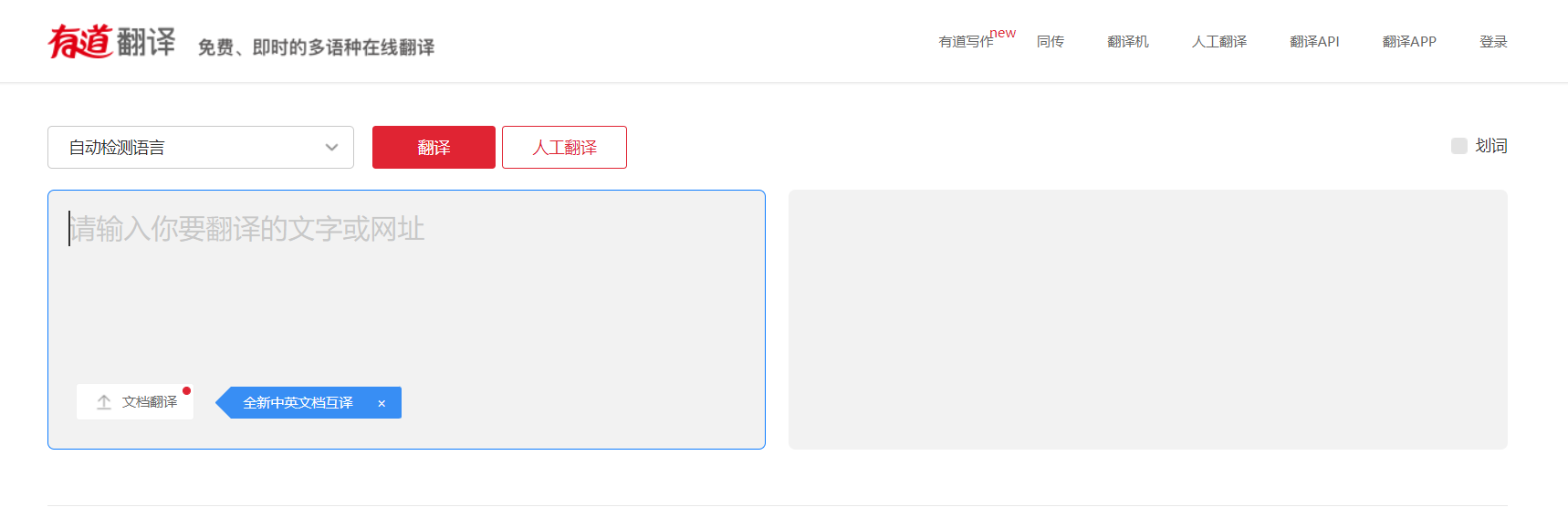
- 稍微使用一下,熟悉网站的逻辑:用户在左侧输入框中输入文字后,右侧会给出实时翻译结果。既然是实时结果,就代表它使用了异步请求的方式
- 我们可以在网络请求记录中找到对应的请求:打开开发者工具,切换到“网络”选项卡,在左侧输入内容,右侧就会得到相应的结果。可以看到,刚才产生了几条请求:

- 根据经验,我们首先怀疑类型为
xhr 的请求,点开一看,果然是 POST 请求,此时已经基本确定无疑了。点开响应面板,果然看到了我们想看到的东西,此请求的响应内容中包含翻译结果:

- 既然这样,那就把请求的网址、表单数据都复制过来,试一试:
import requests
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
datavalue = {
"i": "编程",
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "16532282502370",
"sign": "d4d53c136009fe38f4b465cf19fb6e5c",
"lts": "1653228250237",
"bv": "1744f6d1b31aab2b4895998c6078a934",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION"
}
r = requests.post(url, data=datavalue)
print(r.text)
-
然而,事实并不是这么美好,返回结果是:{"errorCode":50},不是我们想要的 {"errorCode":0,"translateResult":[[{"tgt":"programming","src":"编程"}]],"type":"zh-CHS2en","smartResult":{"entries":["","programme\r\n","programming\r\n"],"type":1}}
-
这是怎么回事呢?因为此网站使用了验证签名的反爬虫手段,这就是今天要学的内容
尽管我在一本书上看到过,把请求网址中的 _o 删掉(即把网址换成 https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule)也能成功得到结果,但是今天是要学习新知识的,假装不知道
概念了解
- 签名是根据数据源进行计算或加密的过程,签名的结果是一个具有唯一性和一致性的字符串
- 签名验证是防止恶意链接和数据被篡改的有效方式之一,也是目前后端 API 最常用的防护方式之一。与 cookie、user-agent、host 和 referer 等请求头域不同,用于签名验证的信息通常被放在请求正文中发送到服务器端
- 签名验证有很多种实现方式,但原理都是相同的:由客户端生成一些随机值和不可逆的 MD5 加密字符串,并在发起请求时将这些值发送给服务器端。服务器端使用相同的方式对随机值进行加密计算以及 MD5 加密,如果服务器端得到的 MD5 值与前端提交的 MD5 值相等,就代表是正常请求,否则返回 403
上手实验
-
在刚才复制 POST 请求的表单数据的时候,有很多参数。其中有一些以短小精悍著称,我们望而知意,对它们根本就产生不了一丝的兴趣,比如:i, from, doctype 等;还有一些奇奇怪怪的参数,成功引起了我们的注意,比如:salt, sign, lts 等
-
我们贯彻胡适先生“大胆假设,小心求证”的思想,在观察和猜测后,得出一些结论:
- salt, sign, lts, bv 这四个参数可能是随机生成的用于反爬虫的字符串
- sign, bv 的值都是长度为 32 位的随机字符串,应该是 MD5 加密后得到的值
- salt 和 lts 的值相似度很高,前者比后者多了 1 位数字。经过多次测试发现,lts 的值是用户在左侧输入文字后自动翻译时生成的 13 位时间戳;salt 比 lts 多出来的一位数在 0 到 9 中随机生成
-
使用不同的浏览器观察请求正文中的 bv 字段值,测试发现,使用相同浏览器发出请求时,bv 字段值是相同的,而使用不同浏览器发出请求时,bv 字段的值是不同的。这说明 bv 的值可以复用,并且它与 ua 或者浏览器版本信息有关
我们对 salt, lts, bv 这三个参数有了一些猜测,还剩下 sign 。既然这种反爬手段叫“签名验证”,那么叫 sign 的参数自然是最后出场,所占篇幅也是最多的
以下就要去 js 文件里找 sign 的生成规则了。虽然我只会 python ,但这就够了,看得多了明白的就多了,多碰壁就有了经验。所以只要 python 入门,应该都会
- sign 字段的值在每一次触发翻译操作时都会变化。在观察请求记录时,可以发现网页加载了名为 fanyi.min.js 的文件
接下来书里没有说怎么找,直接给出了关键代码。所以应该是根据经验找的吧。。。下面的是我根据答案推导做题步骤:
- 点开这个文件,发现好像只有一行,其实不完全是,因为这一行有 223230 列,有 223229 个字符。莫慌张,全选复制,找个网站格式化一下,把返回的内容复制到本地解释器里,发现有 8752 行
如果没用过的话,可以先用这个网站:https://tool.oschina.net/codeformat/js/
- ctrl+f 查找
POST,发现有 9 个,一个个的看。发现第 7847 行的这个似乎是我们要找的,因为 url 是我们请求的 url:
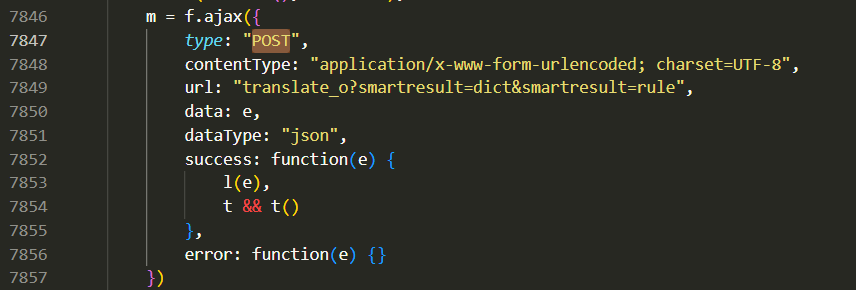
- 第 7850 行表明这个 post 请求的 data 参数是函数 e 给出的,然后接下来就卡住了。。。但是我发现书中给的关键代码,是所有相似代码部分中 data 的参数最多的,即 7473 行的这个:
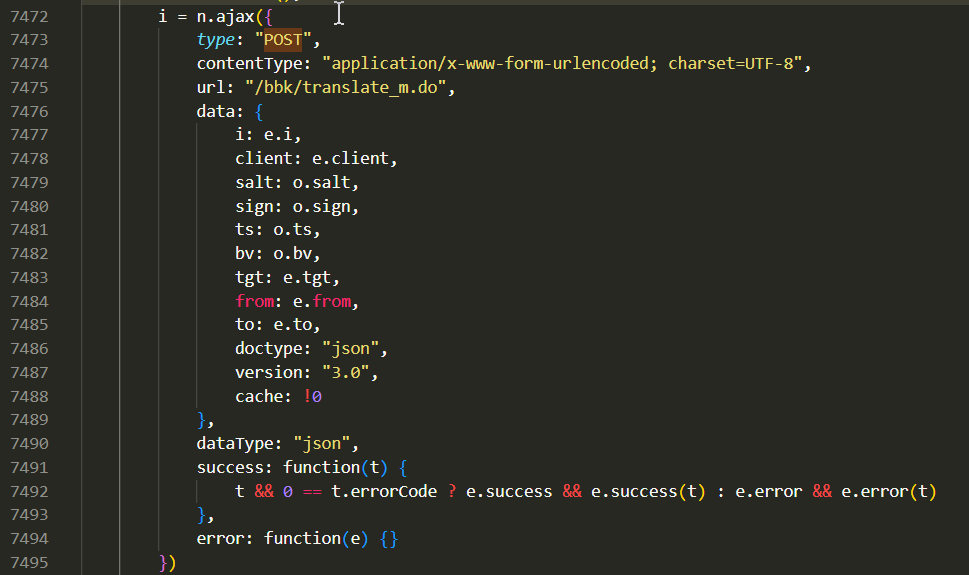
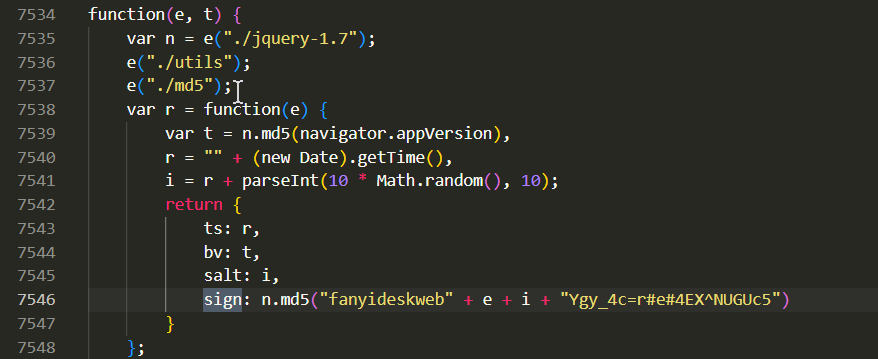
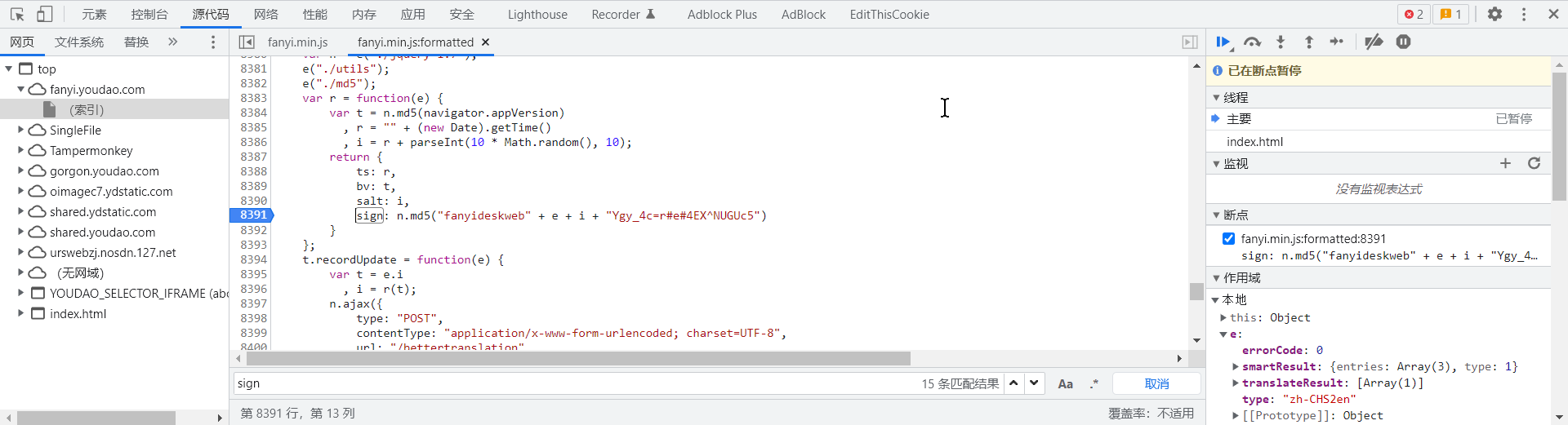
- 根据这段代码,我们可以大胆猜测:请求正文中的字段和对应的值是由 JavaScript 代码生成,为了找到具体的代码,我们搜索关键字 sign 。然后书中就说:最终发现一个用于生成
sign, bv, salt, lts 的方法:
我不知道是怎么发现的,,,
-
我们可以对代码进行如下分析:
- lts 的计算语句是
"" + (new Date).getTime(),其作用是获取当前时间的时间戳
- bv 的计算语句是
n.md5(navigator.appVersion),其作用是获取用 MD5 加密的浏览器信息
- salt 的计算语句是
r + parseInt(10 * Math.random(), 10),其作用是将当前时间戳和 0~9 的随机数字组合成新的字符串
- sign 的计算语句是
n.md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5"),其作用是获取组合字符串的消息摘要值(即 MD5 值)
书上就到此为止了,下面是我东拼西凑来的
from time import time
from random import randint
from hashlib import md5
import requests
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50',
'referer': 'https://fanyi.youdao.com/',
'cookie':'JSESSIONID=abca9UpKky8Ee-wQefdcy; OUTFOX_SEARCH_USER_ID_NCOO=223195183.89224002; _ga=GA1.2.917515912.1651731008; OUTFOX_SEARCH_USER_ID="-1666008210@10.110.96.157"; fanyi-ad-id=305838; fanyi-ad-closed=0; ___rl__test__cookies=1653377328195'
}
lts = str(int(time() * 1000))
salt = lts + str(randint(1,9))
e = "编程"
sign = md5(("fanyideskweb" + e + salt + "Ygy_4c=r#e#4EX^NUGUc5").encode('utf-8')).hexdigest()
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
datavalue = {
"i": "编程",
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"lts": lts,
"bv": "1744f6d1b31aab2b4895998c6078a934",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
r = requests.post(url, data=datavalue, headers=HEADERS)
print(r.text)
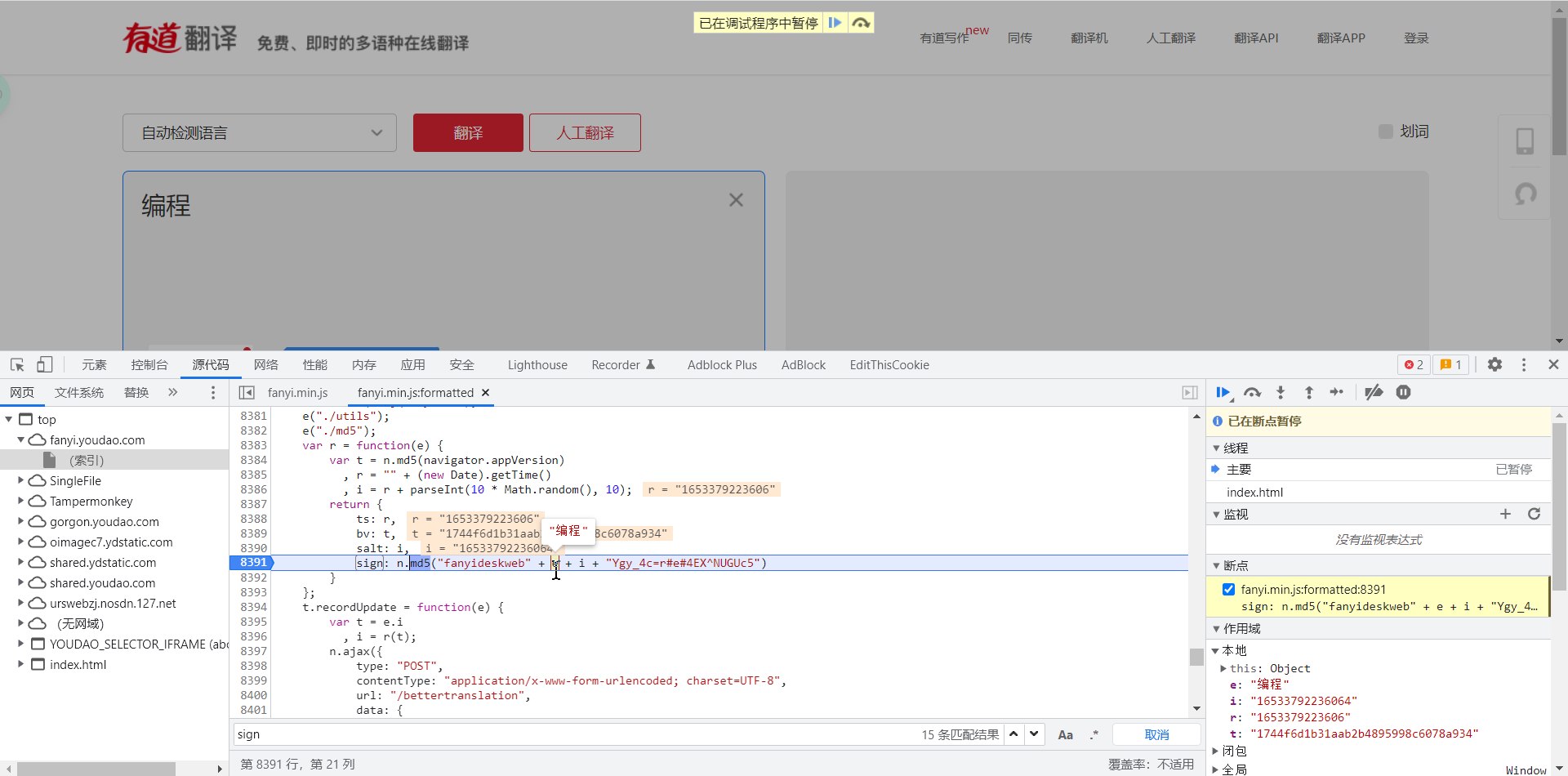
headers 中的三个参数必不可少。cookie 的有效期挺长的,我在网上复制了一个去年 6 月份发的文章的 cookie,都能用
-
运行后成功得到结果
-
不积硅步,无以至千里。学问积年而成,每日不自知



 发表于 2022-5-24 16:42
发表于 2022-5-24 16:42





 收藏
收藏 淘帖
淘帖 有用
有用 分享到朋友圈
分享到朋友圈