示例网址:http://www.qibookw.com/book/7/7132/
网页分析
- 通过审查元素发现所有的章节目录都在元素ID为:
chapterlist的<ul>标签下面
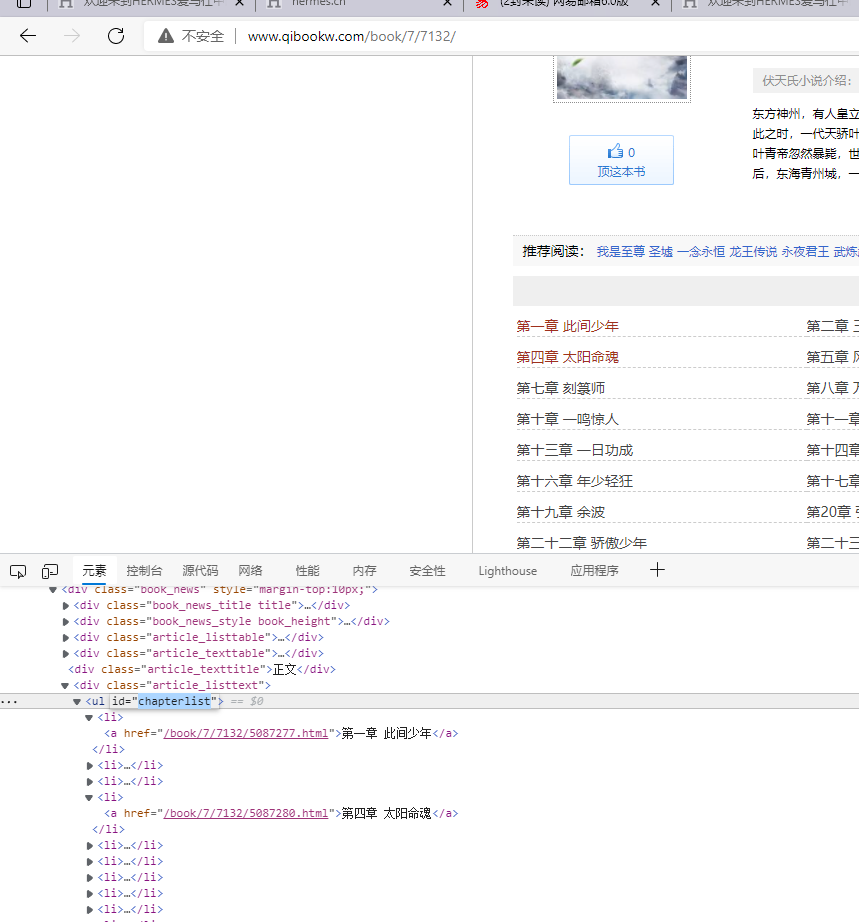
- 此时我们需要获取
<li>标签是数量,然后循环遍历获取到每一章的的URL链接
- 打开获取到的URL链接发现每章的内容都是在
ID为novel_content的div下面
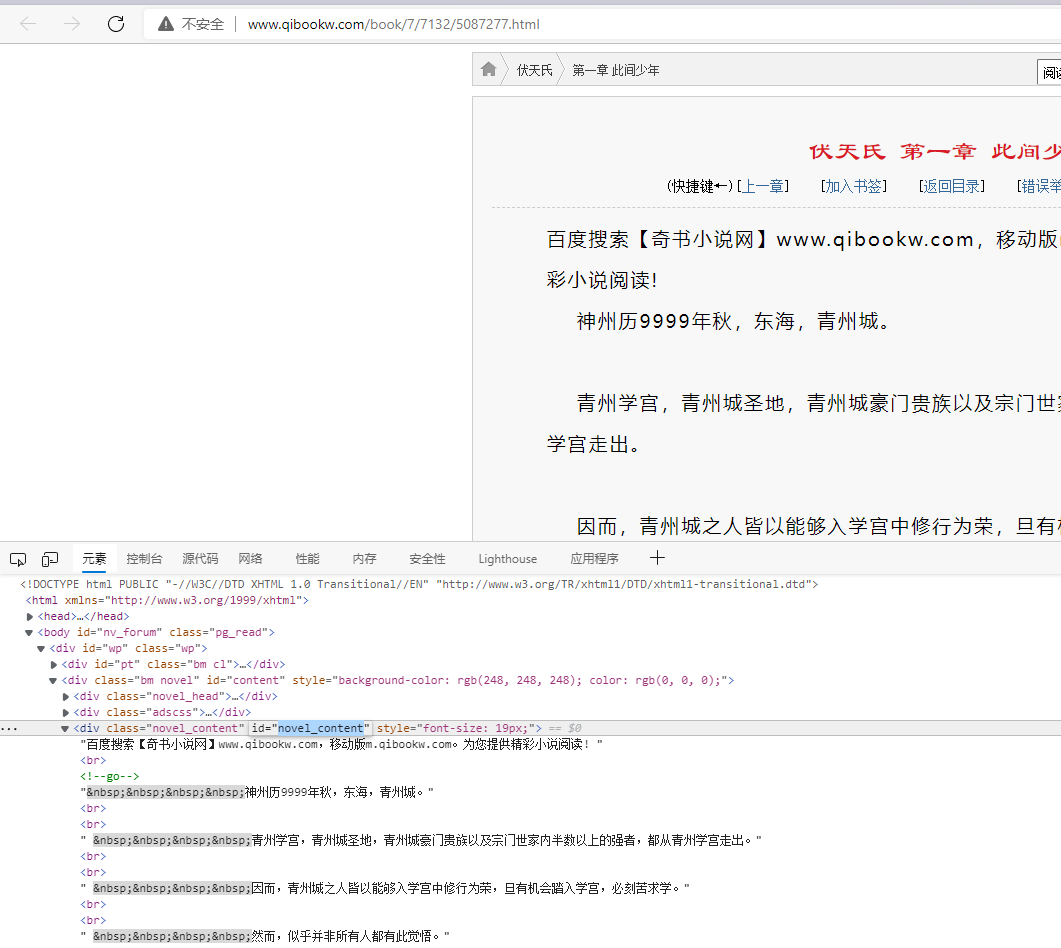
- 此时我们只需要获取到这个ID下面的text值就能获取到文章的内容
代码实现
依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.15</version>
</dependency>
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
Java代码
/**
* home.php?mod=space&uid=686208 无缺
* @ClassName test01
* home.php?mod=space&uid=686237 2021/12/30 9:57
* @Description TODO
*/
public class test01 {
public static void main(String[] args) {
//向这个篇小说所在的主页发送请求,并获取到HTML文档
String body = HttpRequest.get("http://www.qibookw.com/book/7/7132/").execute().body();
//使用jsoup解析得到的html
Document parse = Jsoup.parse(body);
//使用select查询出所有的li标签
Elements li = parse.select("#chapterlist > li");
//根据li的数量循环遍历
for (int i = 1; i < li.size(); i++) {
//根据遍历的i值获取href标签中的url
String href = parse.select("#chapterlist > li:nth-child(" + i + ") > a").attr("href");
StaticLog.info("{}",href);
//获取每章的标题
String title = parse.select("#chapterlist > li:nth-child(" + i + ") > a").text();
//拼接URL
String url = "http://www.qibookw.com" + href;
StaticLog.info("url:{}",url);
//根据得到的URL发送get请求
String body1 = HttpRequest.get(url).execute().body();
//解析请求得到的HTML
Document parse1 = Jsoup.parse(body1);
//获取文章正文
String content = parse1.select("#novel_content").text();
StaticLog.info("当前爬取的文章标题是:{},内容是:{}",title,content);
//构建文章保存的路径
FileWriter fileWriter = new FileWriter("E:\\文档\\xs\\" + title + ".txt");
//写入文章的内容
fileWriter.write(content);
}
}
}
| 
 [复制链接]
[复制链接]
 发表于 2021-12-30 12:41
发表于 2021-12-30 12:41
 |
发表于 2022-11-21 10:51
|
发表于 2022-11-21 10:51



