之前的python爬虫练习之作,今天测试了下,还可以用,话不多说,先直接上同步版本。
comic.py
[Python] 纯文本查看 复制代码 #!/usr/bin/env python
# -*- coding: utf-8 -*-
# [url=home.php?mod=space&uid=238618]@Time[/url] : 2021/4/30 21:33
# [url=home.php?mod=space&uid=686208]@AuThor[/url] : yinghihi
import requests
import re
import os
from lxml import etree
from requests.exceptions import RequestException
from threading import Thread
requests.DEFAULT_RETRIES = 5
requests = requests.session()
requests.keep_alive = False
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.46'}
def get_url(url):
"""网页请求"""
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
html_res = response.text
# 搜索结果超过48后进行分页匹配
search_page_num_re = re.compile('<option value="/search\?q=.*?(p=\d+)".*?>第.*?页</option>', re.S)
search_page_num = re.findall(search_page_num_re, html_res)
s_url_res = []
for n in search_page_num:
s_url = url + '&' + n
s_url_s = requests.get(s_url, headers=headers).text
s_url_res.append(s_url_s)
return s_url_res
except RequestException as e:
raise
def select_comic(s_url_res):
# 搜索结果判断,无结果则提示重新输入
if not s_url_res:
print("抱歉,没有找到符合条件的漫画(*'ω' *)")
print('*' * 60)
url2 = 'https://www.manhuadb.com/search?q=' + input('请重新输入漫画名/作者:')
main(url2)
# 初始化一个以1开始的索引数字序列和索引字典index_dict
num = 1
index_dict = {}
# 有搜索结果,则遍历所有搜索结果的标题和网址
print('搜索到以下结果:')
print('*' * 60)
for html_res in s_url_res:
parse_html = etree.HTML(html_res)
search_title = parse_html.xpath('//div[contains(@class,"comicbook-index")]/a/@title')
search_title_url = parse_html.xpath('//div[contains(@class,"comicbook-index")]/a/@href')
# 定义一个空列表来存放所有搜索到的漫画完整url地址
search_title_url_full = []
for i in search_title_url:
# 拼接出完整的漫画浏览页网址
i = 'https://www.manhuadb.com' + i
search_title_url_full.append(i)
# 将所有搜索到的漫画标题和url合并为一个有对应关系的字典
search_dict = dict(zip(search_title, search_title_url_full))
for k, v in search_dict.items():
# 将数字序列和字典键值拼接展示给用户(用户选择)
print(str(num) + ',' + k + ':' + v)
# 创建一个键从1开始递增,值为url的索引字典(用于爬虫选择要爬取的url)
index_dict[num] = v
num += 1
print('*' * 60)
# 用户输入要下载漫画序号,和索引字典的键对比,相等则爬取对应的漫画url
select_num = int(input('请输入你要下载的漫画序号:'))
for key, value in index_dict.items():
if key == select_num:
select_url = index_dict[key]
select_url_html = requests.get(select_url, headers=headers).text
# 漫画版本下载控制
version_parse = etree.HTML(select_url_html)
version = version_parse.xpath('//ul[contains(@id,"myTab")]/li[@class="nav-item"]/a/span/text()')
version_id = version_parse.xpath('//ul[contains(@id,"myTab")]/li[@class="nav-item"]/a/@href')
version_f_id = []
for v_id in version_id:
version_f_id.append(v_id[1:])
version_dict = dict(zip(version, version_f_id))
v_name = version_parse.xpath('//div[contains(@class,"comic-info")]/h1/text()')[0]
print(f'你选择的漫画【{v_name}】有以下版本可以选择:')
for version_title in version:
print(f'{version_dict[version_title]}=>{version_title}')
print('*' * 60)
select_ver_num = (input('请输入版本序号:'))
version_url = version_parse.xpath(f'//div[@id="{select_ver_num}"]//li/a/@href')[0]
final_url = 'https://www.manhuadb.com' + version_url
final_content = requests.get(final_url, headers=headers).text
return final_content
else:
continue
def parse_html(res):
all_cha_recompile = re.compile(
'<li class="sort_div.*?" data-sort="\d+">\n.*?<a class=".*?" href="\/manhua\/(.*?)">.*?<\/a>\n.*?<\/li>',
re.S)
all_cha_url = re.findall(all_cha_recompile, res)
for i in all_cha_url:
all_full_url = 'https://www.manhuadb.com/manhua/' + i
all_full_content = requests.get(all_full_url, headers=headers).text
page_num_recompile = re.compile(
'<li class="breadcrumb-item active" aria-current="page">\n.*?<a href="\/manhua\/.*?">.*?<\/a> \/ 第 <span class="c_nav_page">\d+<\/span> 页・共 (\d+) 页\n.*?<\/li>',
re.S)
page_nums = re.findall(page_num_recompile, all_full_content)
for num in range(1, int(page_nums[0]) + 1):
full_urls = all_full_url[:-5] + '_p' + str(num) + all_full_url[-5:]
cox = requests.get(full_urls).text
yield cox
def img_parse(img_content):
for item in img_content:
title_recompile = re.compile(
'<li class="breadcrumb-item active" aria-current="page">\n.*?<a href="\/manhua\/.*?">(.*?)<\/a> \/ 第 <span class="c_nav_page">\d+<\/span> 页・共 \d+ 页\n.*?<\/li>',
re.S)
recompile = re.compile(
'<img class="img-fluid show-pic" src="(.*?)" />', re.S)
title = re.findall(title_recompile, item)[0]
src = re.findall(recompile, item)[0]
pic_request = requests.get(src, headers=headers)
img_name_re = re.compile(
'<img class="img-fluid show-pic" src="https:\/\/i\d+.manhuadb.com\/.*?\/.*?\/.*?\/(.*?)" />', re.S)
img_name = re.findall(img_name_re, item)[0]
comic_name_re = re.compile('<h1 class="h2 text-center mt-3 ccdiv-m"><a href=".*?">(.*?)<\/a><\/h1>', re.S)
comic_name = re.findall(comic_name_re, item)[0]
yield {'comic_name': comic_name, 'img_name': img_name, 'img_content': pic_request.content,
'chapter_title': title}
def write_res(item):
comic_path = item['comic_name']
dict_res = item['chapter_title']
if not os.path.exists(comic_path + '/' + dict_res):
os.makedirs(comic_path + '/' + dict_res)
with open(comic_path + '/' + dict_res + '/' + item['img_name'], 'wb') as f:
print('正在下载:' + dict_res + '/' + item['img_name'])
f.write(item['img_content'])
else:
if os.path.exists(comic_path + '/' + dict_res + '/' + item['img_name']):
print(f'{item["img_name"]}已存在,忽略下载!!!')
else:
with open(comic_path + '/' + dict_res + '/' + item['img_name'], 'wb') as f:
print('正在下载:' + dict_res + '/' + item['img_name'])
f.write(item['img_content'])
def thredings(img_res):
for item in img_res:
t = Thread(target=write_res, args=(item,))
t.start()
def main(offset):
html = get_url(offset)
selecter = select_comic(html)
print('资源序号已选择,开始解析!')
response = parse_html(selecter)
print('页面解析完毕,获取所有漫画页面资源中···!')
img_res = img_parse(response)
print('开始下载···')
print('*' * 60)
# write_res(img_res)
thredings(img_res)
if __name__ == '__main__':
print('=====程序开始执行=====')
url = 'https://www.manhuadb.com/search?q=' + input('请输入漫画名/作者:')
main(url)
截图
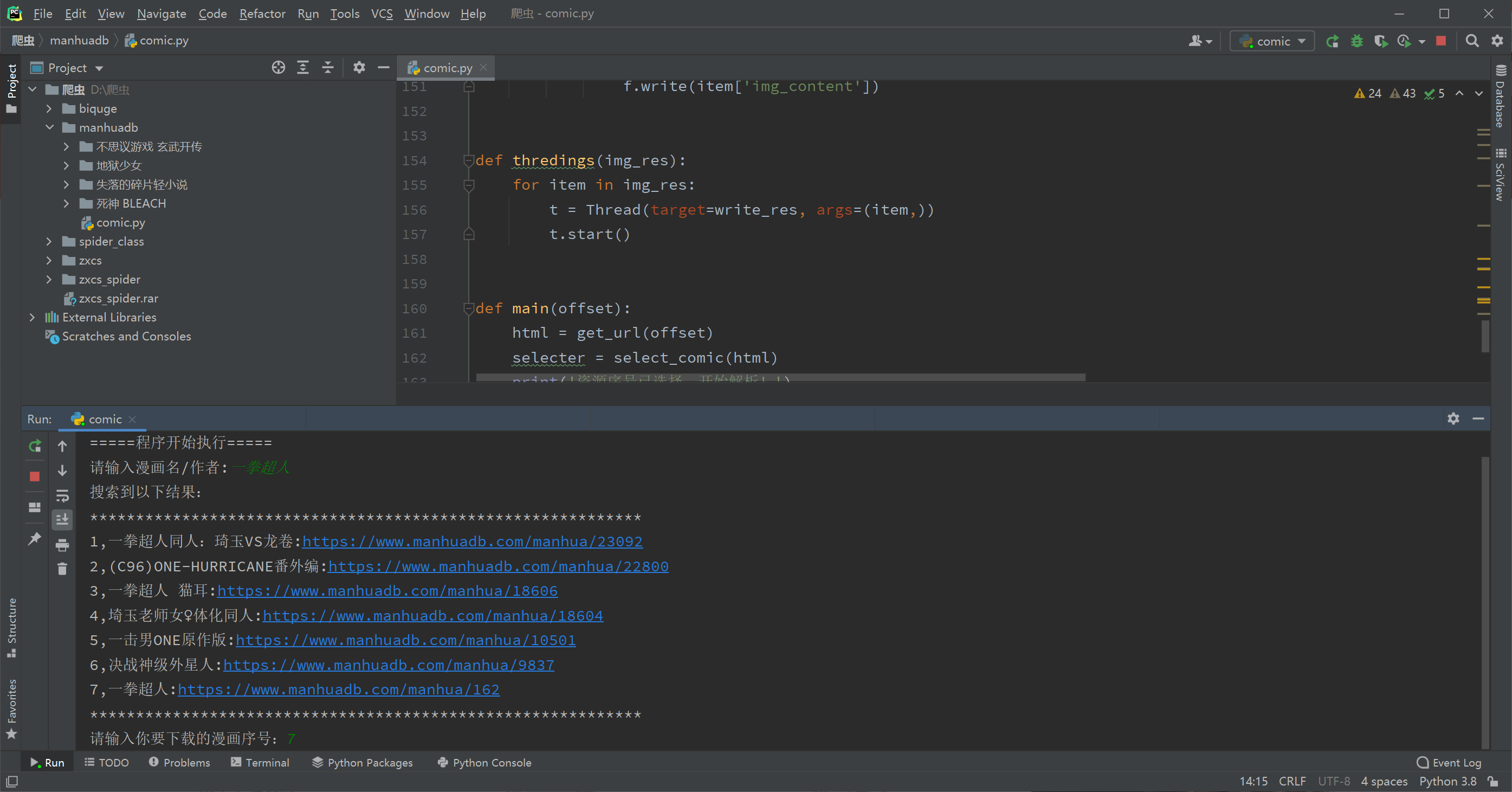
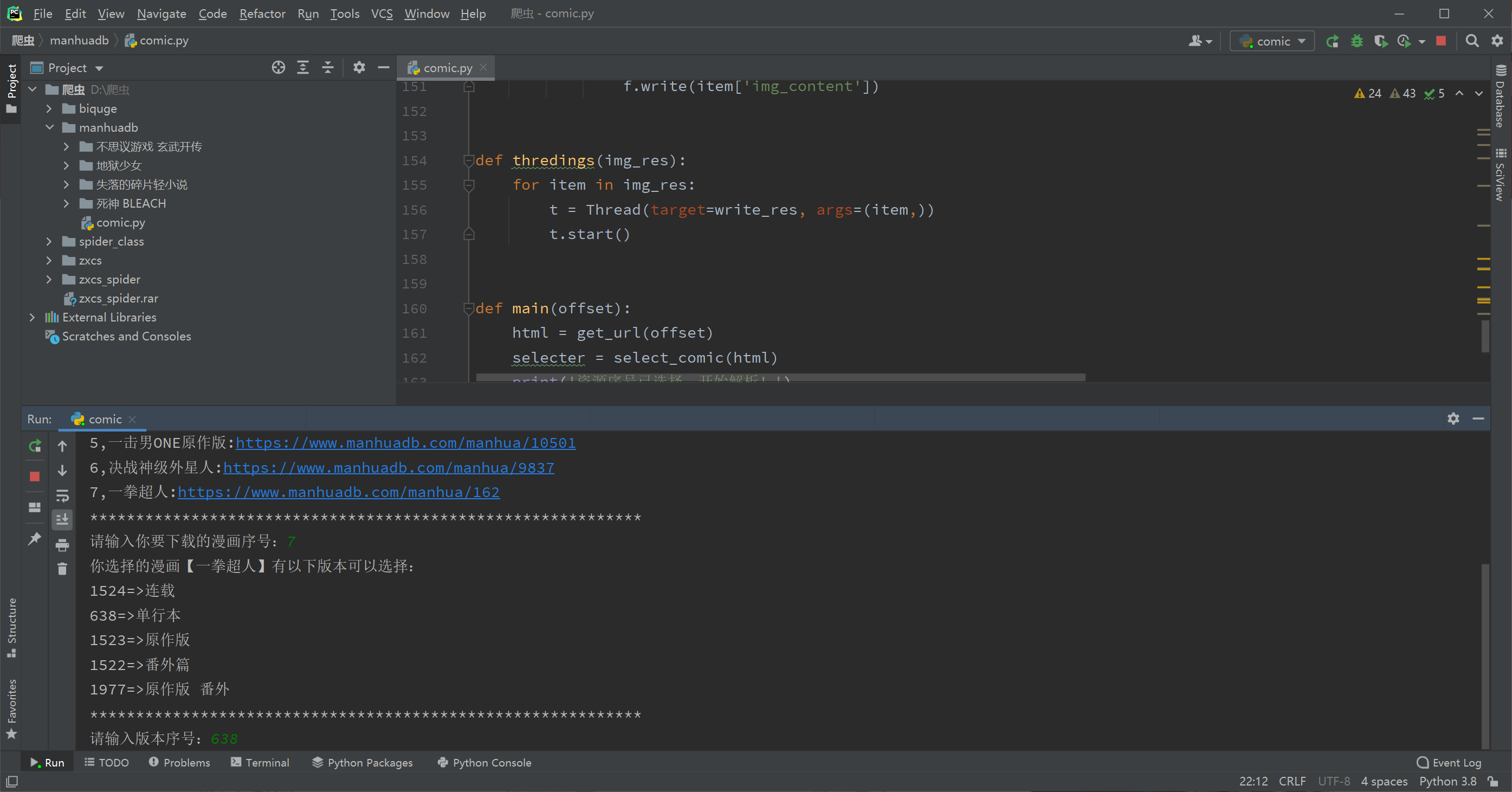
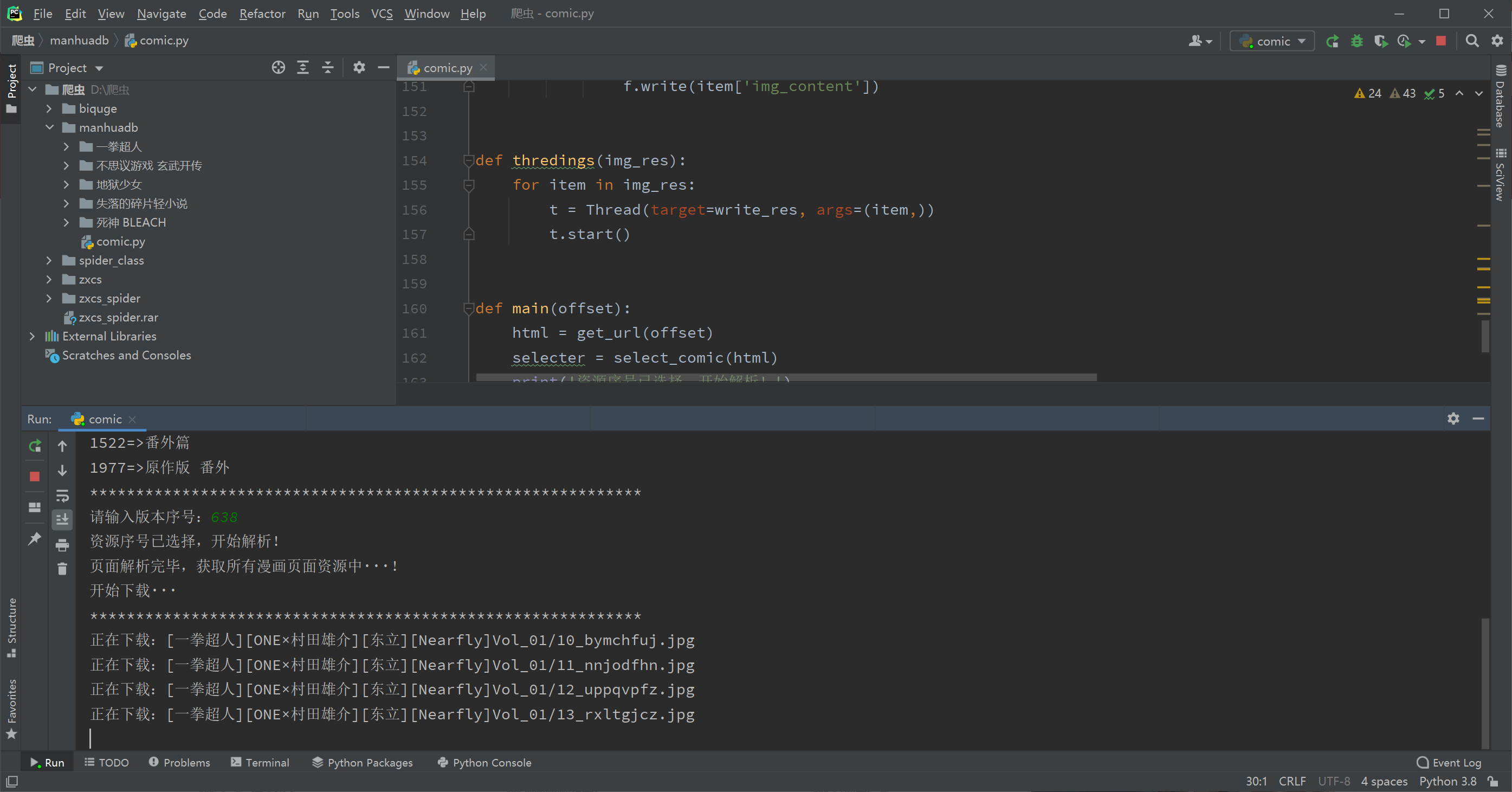

重点来了,先吹一波异步协程的效率,对比用requests同步请求下载的爬虫,快了10倍不止。如果大家想真的写出个实用的高效爬虫,异步绝对不能不了解。
我也是经过不断试错,今天才算勉强了解asyncio和aiohttp的基本用法,网上能用于实战的教程实在太少了,大部分都是雷同的,想请教下坛子里的大佬们,不知道哪里能找到比较完善易懂的异步教程。
下面关于我写的这个爬虫异步版本:
因为是验证异步下载效果的,所以很多变量和代码就写的很随便了,很难读。另外就是异步爬虫的异常捕获我还不会,细节有待完善,等我完善好再发出来,今天主要先安利一波,发截图给大家看看异步的效率。
这里以下载漫画【死神】为例:(74卷,2.99GB,13973张,因为网站在国外,晚上速度不理想,用requests请求基本1-2秒一张,数量太多没测试完)
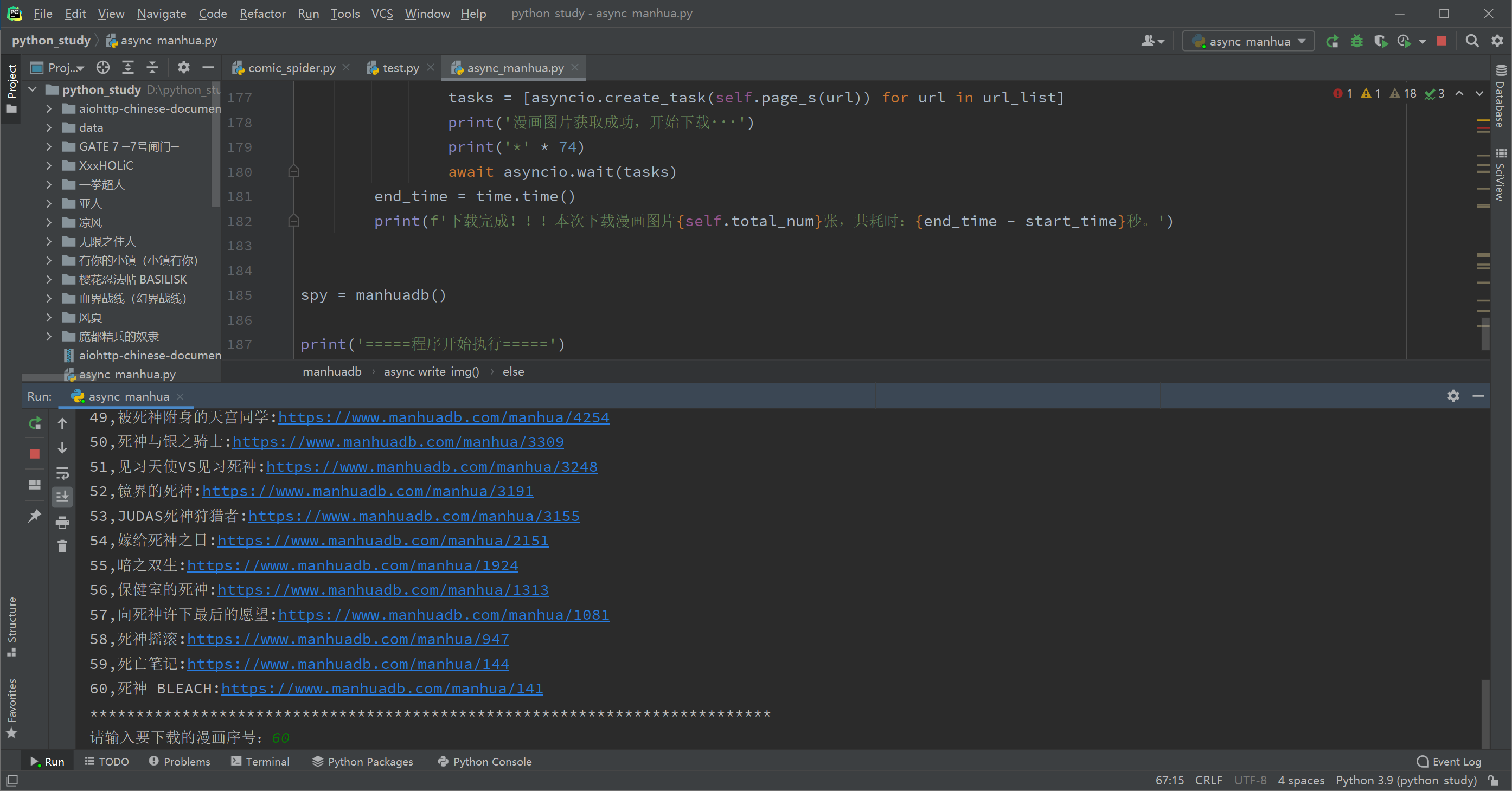
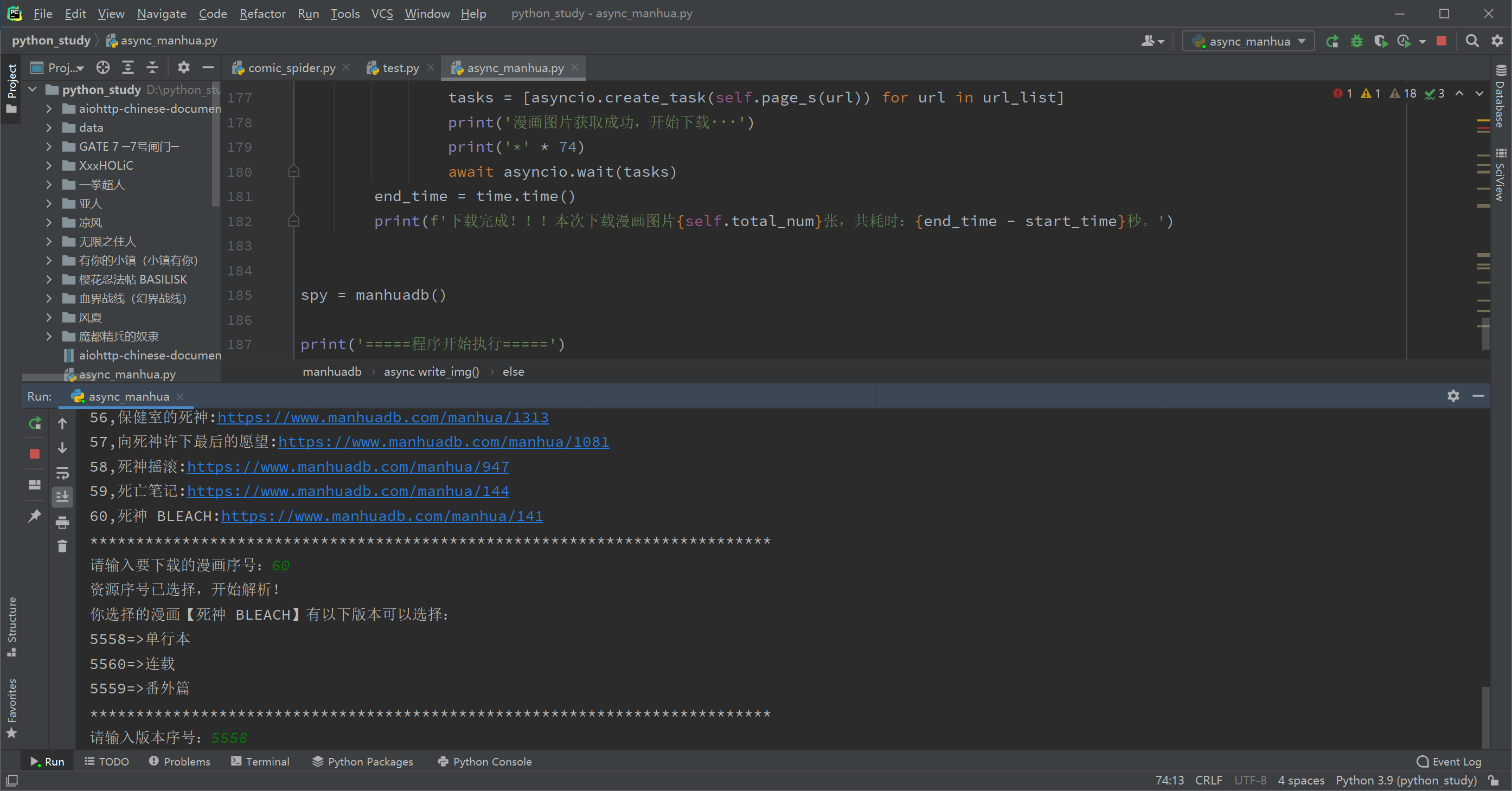
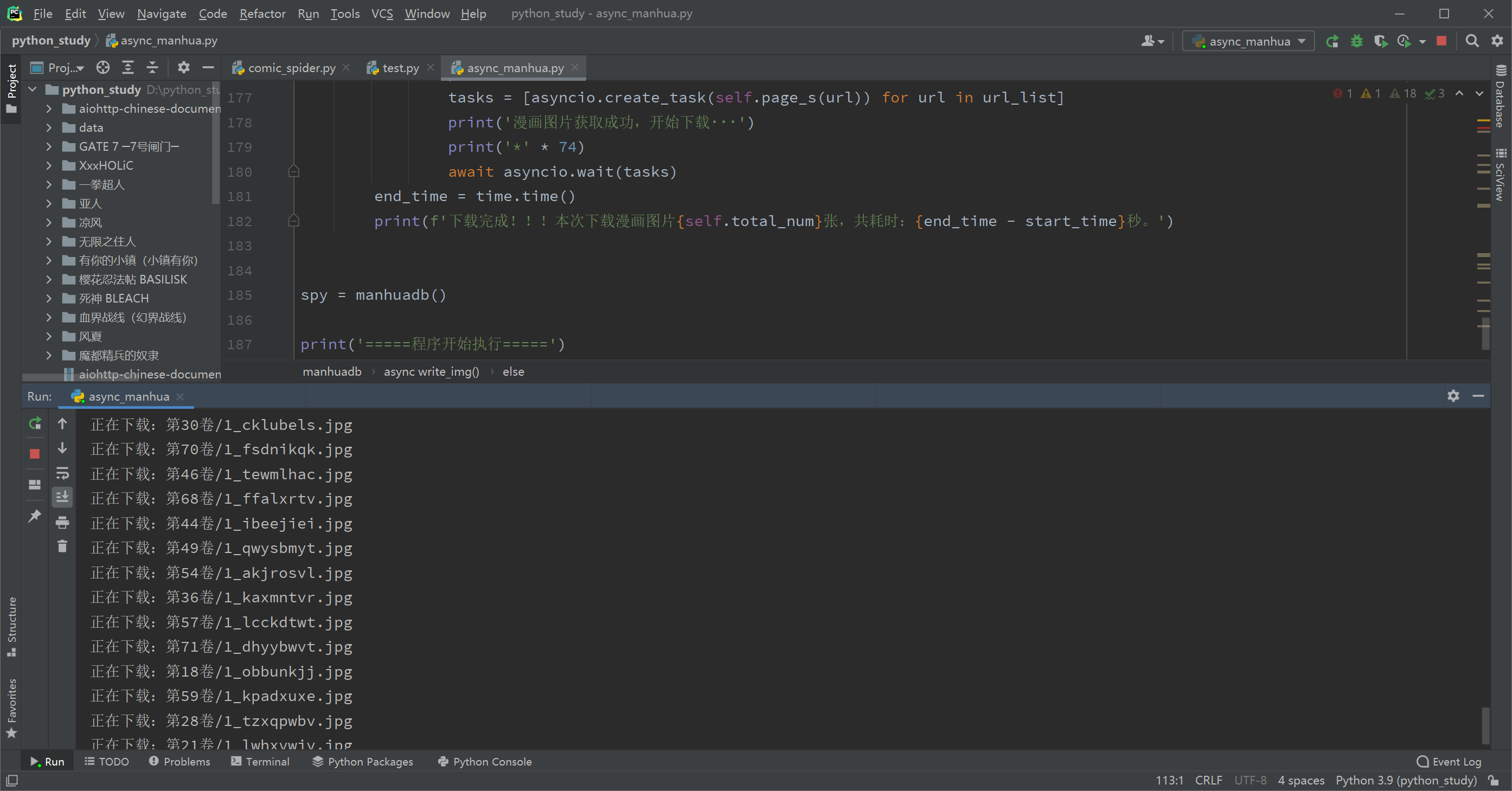
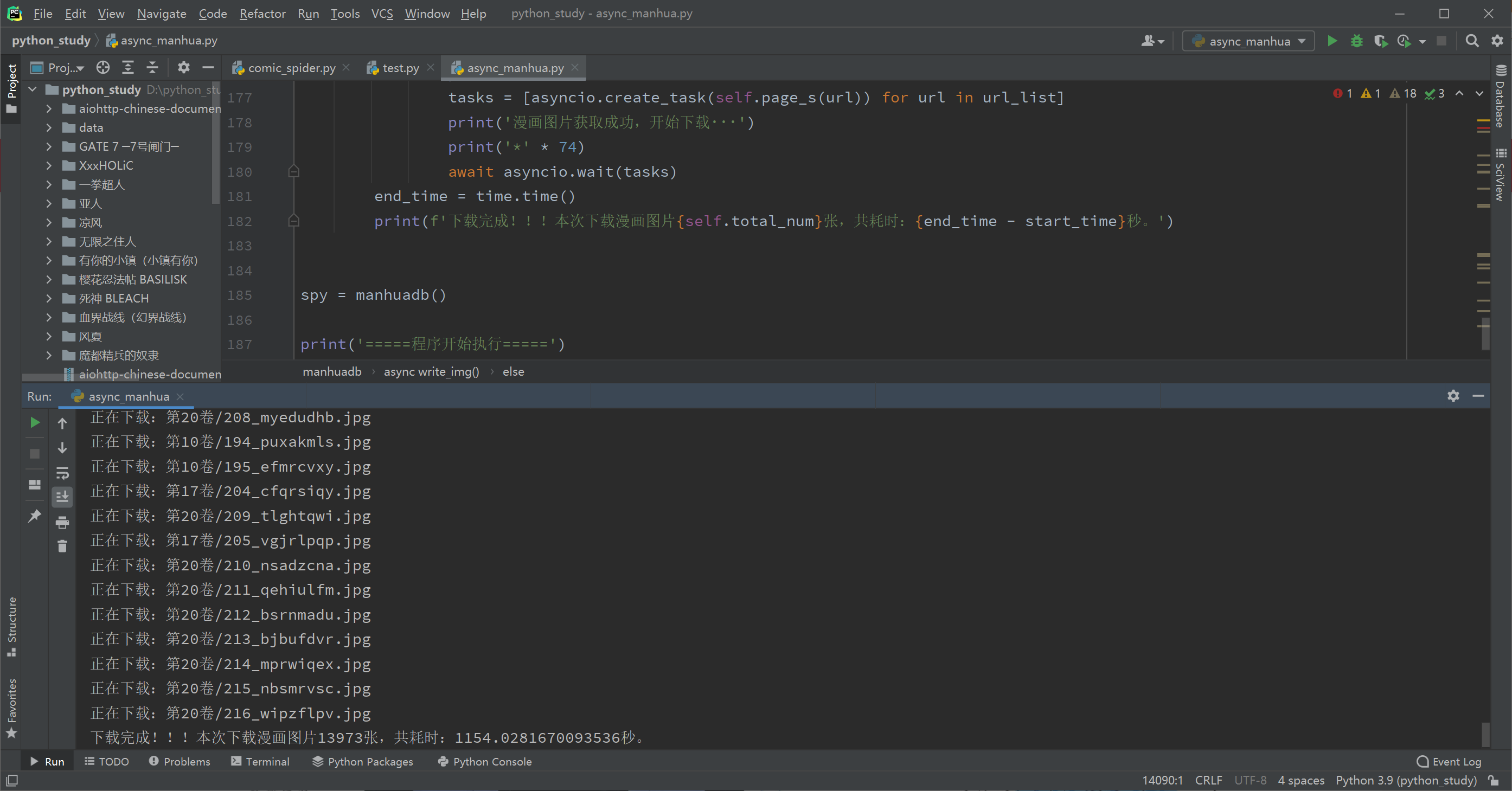
可以看到,爬完整部漫画,用异步只需要1154秒(如果是白天网速理想的情况下,应该可以更快的),而如果用同步至少要14000秒以上了,明显异步要更实用些。 | 
 [复制链接]
[复制链接]
 发表于 2021-7-1 00:06
发表于 2021-7-1 00:06





