B站视频多线程10倍速下载!哔哩哔哩bilibili。
先上成果图
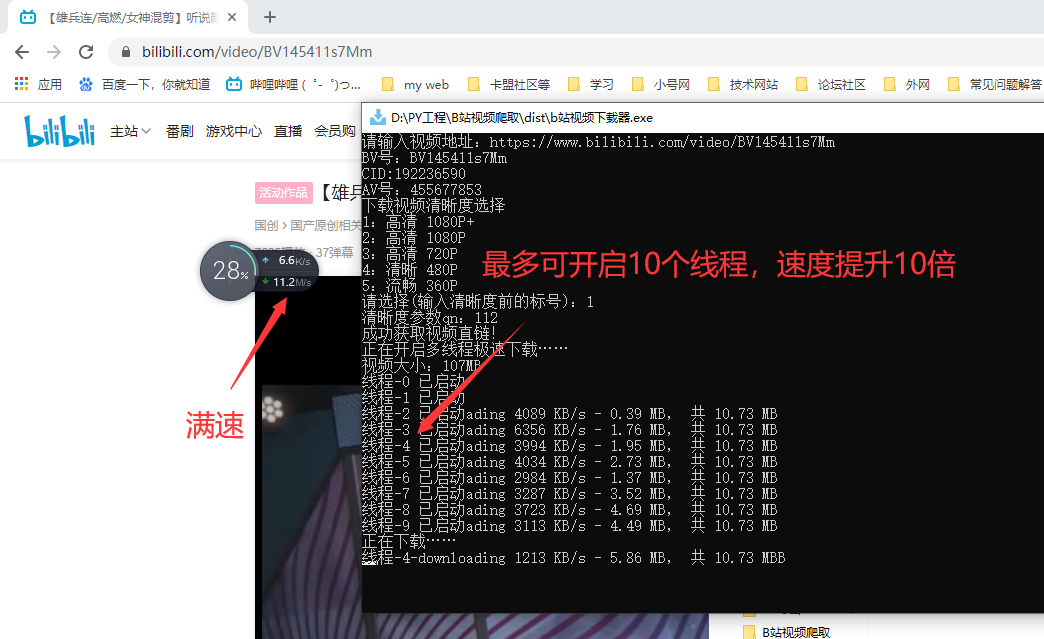
线程数由你下载的文件大小决定的,小文件一个线程就够了,大文件最多会开启10个线程,也就是10倍速下载!
代码分两个文件,一个是主文件,一个是写多线程的
这是主文件
import requests
import re
import json
from multithreading import thread
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
url = input("请输入视频地址:")
with open('SESSDATA.txt', 'r') as f:
SESSDATA = f.read()
if SESSDATA == '0':
print('检测到您未设置SESSDATA,最高只能下载480p画质哦!')
#获取BV号
if '?' in url:
url = url.split('?')[0]
print(url)
bvid = re.search(r'BV.*', url).group()
print('BV号:'+bvid)
#获取cid
cid_json = requests.get('https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'.format(bvid)).text
cid = re.search(r'{"cid":(\d+)', cid_json).group()[7:]
print('CID:'+cid)
#获取视频的av号
rsp = requests.get(url, headers=headers)
aid = re.search(r'"aid":(.*?),"', rsp.text).group()[6:-2]
print('AV号:'+aid)
#抓取视频真实地址,清晰度
qn = 16 #先设置一个默认低清晰度
headers['Referer'] = url
api_url = 'https://api.bilibili.com/x/player/playurl?cid={}&avid={}&qn={}&otype=json&requestFrom=bilibili-helper'.format(cid, aid, qn)
qn_dict = {}#用来存放清晰度选择参数
rsp = requests.get(api_url, headers=headers).content
rsp = json.loads(rsp)
qn_accept_description = rsp.get('data').get('accept_description')
qn_accept_quality = rsp.get('data').get('accept_quality')
print('下载视频清晰度选择')
for i, j, xuhao in zip(qn_accept_description, qn_accept_quality, range(len(qn_accept_quality))):
print(str(xuhao+1)+':'+i)
qn_dict[str(xuhao+1)] = j
xuhao = input('请选择(输入清晰度前的标号):')
qn = qn_dict[xuhao]
print('清晰度参数qn:'+str(qn))
api_url = 'https://api.bilibili.com/x/player/playurl?cid={}&avid={}&qn={}&otype=json&requestFrom=bilibili-helper'.format(cid, aid, qn)
#print('api_url='+api_url)
cookies = {}
cookies['SESSDATA'] = SESSDATA #这里输入你的SESSDATA
rsp = requests.get(api_url, headers=headers, cookies=cookies).content #这里代cookies才能得到会员或者登录后才能下载的视频的链接
rsp = json.loads(rsp)
real_url = rsp.get('data').get('durl')[0].get('url')
print('成功获取视频直链!')
print('正在开启多线程极速下载……')
thread(real_url, url, 'b站视频.flv')#多线程下载
#把上面那行删掉,把下面注释去掉就是单线程下载
#content = requests.get(real_url, headers=headers).content
#with open('1.flv', 'wb') as f:
# f.write(content)
这是多线程文件:
import requests
import threading
import datetime
import time
#改headers参数和url就好了
def thread(url, Referer, file_name):
# print(r.status_code, r.headers)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'Referer': Referer
}
r = requests.get(url, headers=headers, stream=True, timeout=30)
all_thread = 1
# 获取视频大小
file_size = int(r.headers['content-length'])
# 如果获取到文件大小,创建一个和需要下载文件一样大小的文件
if file_size:
fp = open(file_name, 'wb')
fp.truncate(file_size)
print('视频大小:' + str(int(file_size / 1024 / 1024)) + "MB")
fp.close()
# 每个线程每次下载大小为5M
size = 5242880
# 当前文件大小需大于5M
if file_size > size:
# 获取总线程数
all_thread = int(file_size / size)
# 设最大线程数为10,如总线程数大于10
# 线程数为10
if all_thread > 10:
all_thread = 10
part = file_size // all_thread
threads = []
starttime = datetime.datetime.now().replace(microsecond=0)
for i in range(all_thread):
# 获取每个线程开始时的文件位置
start = part * i
# 获取每个文件结束位置
if i == all_thread - 1:
end = file_size
else:
end = start + part
if i > 0:
start += 1
headers = headers.copy()
headers['Range'] = "bytes=%s-%s" % (start, end)
t = threading.Thread(target=Handler, name='线程-' + str(i),
kwargs={'start': start, 'end': end, 'url': url, 'filename': file_name, 'headers': headers})
t.setDaemon(True)
threads.append(t)
# 线程开始
for t in threads:
time.sleep(0.2)
t.start()
# 等待所有线程结束
print('正在下载……')
for t in threads:
t.join()
endtime = datetime.datetime.now().replace(microsecond=0)
print('下载完成!用时:%s' % (endtime - starttime))
def Handler(start, end, url, filename, headers={}):
tt_name = threading.current_thread().getName()
print(tt_name + ' 已启动')
r = requests.get(url, headers=headers, stream=True)
total_size = end - start
downsize = 0
startTime = time.time()
with open(filename, 'r+b') as fp:
fp.seek(start)
var = fp.tell()
for chunk in r.iter_content(204800):
if chunk:
fp.write(chunk)
downsize += len(chunk)
line = tt_name + '-downloading %d KB/s - %.2f MB, 共 %.2f MB'
line = line % (
downsize / 1024 / (time.time() - startTime), downsize / 1024 / 1024,
total_size / 1024 / 1024)
print(line, end='\r')
if __name__ == '__main__':
url = input('输入视频链接(请输入视频原链):')
thread(url)
这个代码太多了,我就用注释来解释,不单独说明了,如果有不会的就在帖子下面留言,我会的都会帮你解答的。
成品在这里:https://www.52pojie.cn/thread-1203083-1-1.html

 [复制链接]
[复制链接]

 发表于 2020-6-18 21:12
发表于 2020-6-18 21:12
 |
发表于 2020-6-18 21:53
|
发表于 2020-6-18 21:53



 ,还有就是可以研究下多P下载
,还有就是可以研究下多P下载
