简单说明
之前在论坛发现一个很好的小说阅读站,可惜只能在线阅读,无法下载到本地,导出到电子书设备上。恰好最近在学python,于是就有了写一个下载器的想法。
但,对于初学菜鸟、又是初三学子的我,这又谈何容易?一面学习python语法,一面又要学习学校网课、做一大堆作业,哎!
好在,经过十余天的努力,程序完工了!
现阶段是单线程下载,速度较慢(3-5items/s)想向大佬们请教,如何写成多线程?谢谢!
使用教程
1.下载解压附件
2.获取cookies
浏览器打开novel.luckymorning.cn,按下图操作

3.将复制的cookies粘贴到【Settings.json】
请用记事本打开软件目录下的Settings.json文件,将获取的cookies粘贴到引号内(如下图)
"cookie":"填你的cookie"

4.配置下载路径
Settings.json,在引号内填写路径(路径不存在会自动创建)
"save_path":"填你的下载路径"
如C:\\Users\\Administrator\\Desktop
注意双反斜杠"\"以及结尾没有斜杠

5.以管理员身份运行程序
运行前请确保程序与Settings.json文件在同一路径下,否则会报错!
软件运行动图:

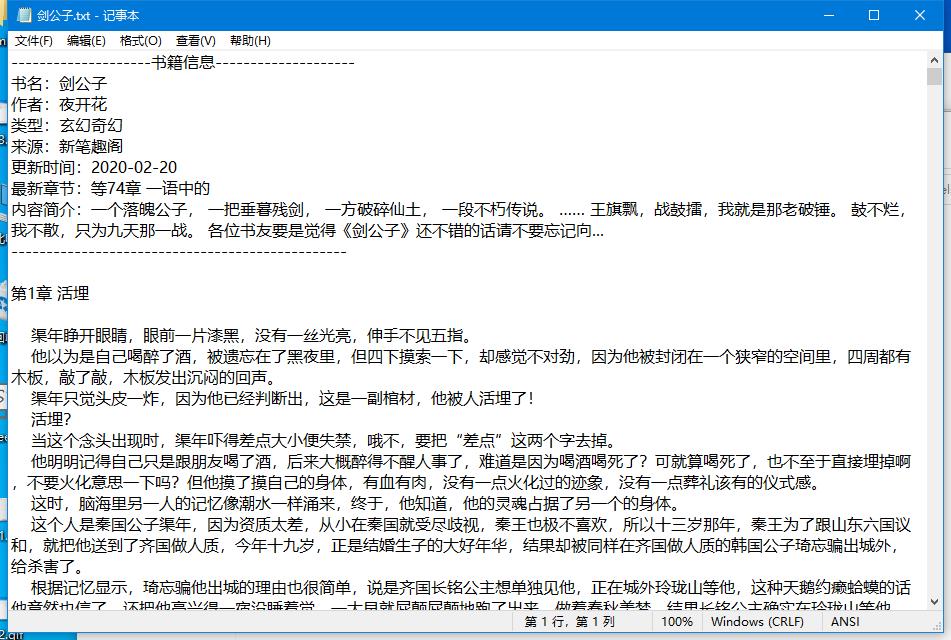
最终效果:
源码公开
requests,lxml,tqdm,fake_useragent,beautifulsoup4是第三方模块,编译运行前记得pip安装!以免报错!
主程序
import json,requests,lxml,os,sys
from time import time,sleep
from tqdm import tqdm
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
def delete_blanks(cons): #删除列表空项目
for con in cons:
if con == '\n':cons.remove(con)
return cons
def tuichu(userin): # 快速退出软件(没啥用)
if userin.lower() == 'exit' or userin == '' or userin==0:
sys.exit()
def change(nstr): # 把bs4字符串转成Unicode字符串
ustr = ''
ustr = ustr.join(nstr)
return ustr
def settings(): #读取设置
with open('Settings.json') as sj:
settings=json.load(sj)
return settings
def makedirs(dir_name): # 创建目录
if os.path.isdir(dir_name) == False:
os.makedirs(dir_name)
def makereq(method,url,data=None): #发送HTTP请求
headers={
'User-Agent':str(UserAgent().random),
'cookie':settings()['cookie']
}
if method=='GET':
try:
r=requests.get(url=url,headers=headers)
r.raise_for_status()
return r.text
except Exception as error:
print(error)
if method=='POST':
try:
r=requests.post(url=url,headers=headers,data=data)
r.raise_for_status()
return r.text
except Exception as error:
print(error)
def get_input(maxint,text):
while True:
userin=input(text)
tuichu(userin)
if userin.isdecimal()==True:
if int(userin)<=maxint:
return int(userin)
break
print('您的输入非法,请重新输入!')
def get_search_objs(): #获取搜索结果
while True:
keyword=input('请输入搜索关键词: ')
tuichu(keyword)
url='http://novel.luckymorning.cn/search'
html=makereq('POST',url,{'name':keyword})
soup=BeautifulSoup(html,'lxml')
trs=soup.find(name='table', attrs={'class': 'layui-tab'}).contents[1].contents
trs=delete_blanks(trs)
if len(trs)!=0:break
else:print('没有匹配的结果,换个关键词试试吧!')
#存储搜索结果,以便后面调用
result={}
results=[]
for tr in trs:
book_info=tr.find(name='td',attrs={'class':'book-info'})
a=book_info.find_all('a')
p=book_info.find_all('p')
result['url']='http://novel.luckymorning.cn/'+change(a[0]['href'])
result['name']=change(p[0].string)
result['des']=p[1].string
result['author']=p[2].string.split(':')[-1]
result['type']=p[3].string.split(':')[-1]
result['update']=p[4].string.split(':')[-1]
result['new']=p[5].string.split(':')[-1]
result['source']=a[1].string
results.append(result)
result={}
return results
def print_search_objs(results): #打印搜索结果
index=0
print('\n搜索结果如下:')
for result in results:
index+=1
print('------------------['+str(index)+']------------------')
print('书名:'+result['name'])
print('作者:'+result['author'])
print('类型:'+result['type'])
print('来源:'+result['source'])
print('更新时间:'+result['update'])
print('最新章节:'+result['new'])
try:
print('内容简介:'+result['des'])
except TypeError:
result['des']='暂无'
print('内容简介:'+result['des'])
print('----------------------------------------')
index=get_input(index,'请输入你选择的书前面的序号[结果总数'+str(index)+'] ')
return index
def get_catalogs(index,result): #获取书籍目录
print('\n正在获取小说目录...')
url=result['url']
html=makereq('GET',url)
soup=BeautifulSoup(html,'lxml')
ecats=soup.find(name='div',attrs={'class':'layui-row catalogs'}).contents
ecats=delete_blanks(ecats)
titles,urls=[],[]
for ecat in ecats:
titles.append(ecat.string)
urls.append('http://novel.luckymorning.cn/'+change(ecat['href']))
print('目录获取成功!共 '+str(len(ecats))+' 章。')
#创建下载目录、txt文件,写入书籍信息
txtname=settings()['save_path']+'\\'+result['name']+'.txt'
makedirs(settings()['save_path']+'\\')
with open(txtname,'w',encoding='UTF-8-sig') as txt:
head='--------------------书籍信息--------------------\n'+'书名:'+result['name']+'\n作者:'+result['author']+'\n类型:'+result['type']+'\n来源:'+result['source']+'\n更新时间:'+result['update']+'\n最新章节:'+result['new']+'\n内容简介:'+result['des']+'\n------------------------------------------------\n'
txt.write(head)
return titles,urls,txtname
def get_chapter(titles,urls,txtname): #处理、下载每章内容
num=get_input(len(urls),'请输入要爬取的章数[总章数'+str(len(urls))+'] ')
print('已开始下载TXT!')
t1=time()
with open(txtname,'a',encoding='UTF-8-sig') as txt:
i=0
pbar=tqdm(urls[:num],desc='-->下载进度',ascii=True) #设置进度条,把ascii改成False就是用[█]填充,True就是用[#,0-9]填充
for url in pbar: #下载每一章
txt.write('\n'+titles[i]+'\n\n') #写入标题
html=makereq('GET',url)
soup=BeautifulSoup(html.replace(' ', ' '),'lxml')
etexts=soup.find(name='div',attrs={'class':'reader-content'}).contents
for etext in etexts:
if etext.name=='br':etexts.remove(etext)
for etext in etexts: #写入每一行
txt.write(change(etext)+'\n')
i+=1
t2=time()
print('已完成下载任务,耗时 '+str(round(t2-t1,3))+' 秒')
def main():
os.system("title TXT小说下载器 [吾爱破解 @lihaisanhui]")
print('欢迎使用TXT小说下载器[Ver.0.1].作者:吾爱破解论坛 @lihaisanhui\n前往源站:novel.luckymorning.cn获取更多精彩内容!\n')
results=get_search_objs()
index=print_search_objs(results)
result=results[index-1]
titles,urls,txtname=get_catalogs(index,result)
get_chapter(titles,urls,txtname)
input('请按[Enter]键退出...')
if __name__ == "__main__":
main()
Settings.json配置文件示例
{
"save_path":"D:\\Novels",
"cookie":"JSESSIONID=A1E9640B8282AAEC74E931FD7FBCA90B; Hm_lvt_b486f018abfcfa6d9b99f75f37cf0852=1581483604,1581483686,1581571096,1581582191; Hm_lpvt_b486f018abfcfa6d9b99f75f37cf0852=1581582194"
}
更新日志
2020/2/21 v0.1.1
修复编码错误导致的意外退出
修复乱码Bug
文件获取


 [复制链接]
[复制链接]

 发表于 2020-2-20 13:26
发表于 2020-2-20 13:26








